一、产品介绍
Google DeepMind 作为谷歌旗下前沿人工智能研究机构,始终致力于推动AI技术的边界。其最新发布的Gemini 2.5计算机使用模型(Gemini 2.5 Computer Use model),并非一个独立的消费级产品,而是一个专为开发者打造的、功能强大的专业化基础模型。该模型基于多模态模型Gemini 2.5 Pro构建,继承并强化了其卓越的视觉理解与推理能力,其核心定位是赋能开发者构建能够直接观察、理解并操作图形用户界面(GUI)的AI智能体(Agent)。
在当前的技术生态中,AI模型与软件交互大多依赖于预先定义好的结构化API。然而,数字世界中仍有大量任务——例如填写复杂表格、操作企业后台管理系统、进行跨平台的流程审批——必须通过视觉识别和模拟点击、输入等人类行为来完成。传统的自动化脚本(如RPA机器人)僵硬且脆弱,无法应对UI布局的微小变动。Gemini 2.5计算机使用模型的诞生,正是为了破解这一自动化难题,其差异化技术亮点在于实现了端到端的视觉-动作闭环。它能够像人一样“看”屏幕截图,理解UI元素的上下文语义,并自主决定下一步的最佳操作,从而处理非结构化的交互任务,甚至应对需要登录验证的复杂场景。
二、技术讲解
该模型的技术核心是一个高效的迭代处理循环,其工作流程清晰且高效。
1. 输入与感知
开发者通过调用Gemini API中的新工具 computer_use 来启动这个循环。每次调用时,需向模型提供三类关键信息:
- 用户指令(User Request):用自然语言描述需要完成的任务,例如“为所有加州居民的宠物安排水疗预约”。
- 环境截图(Screenshot):客户端捕获的当前用户界面(如浏览器窗口、移动应用屏幕)的像素级图像。
- 行动历史(History of Recent Actions):记录之前几步的操作序列,为模型提供上下文,避免重复或无效操作。
2. 分析与决策
接收到这些信息后,模型会运用其强大的多模态能力同时处理文本和图像。它首先解析用户的指令意图,然后像一名人类操作员一样,仔细“审视”屏幕截图,识别出按钮、输入框、下拉菜单、文本内容等所有UI元素,并理解它们之间的逻辑关系。接着,模型会进行推理,判断当前状态下为实现最终目标所应采取的最优单一原子操作。
3. 输出与执行
模型的输出通常是一个函数调用(Function Call),代表其决定执行的UI操作,例如:
click(x, y): 点击屏幕上某个特定坐标。type(text): 在焦点输入框中输入一段文本。scroll(direction): 向上或向下滚动页面。
在某些高风险场景下(如最终确认支付),模型也可能输出一个请求,要求最终用户进行手动确认,以确保安全。
4. 反馈与迭代
客户端代码执行模型给出的动作后,界面状态发生变化。客户端随即捕获一张新的屏幕截图和当前的URL,作为上一次函数调用的响应结果,反馈给模型。模型基于新的“观察”结果,再次进行分析-决策-输出,如此循环往复,直至任务被完成、出现错误或被安全机制终止。
目前,该模型主要针对Web浏览器环境进行了深度优化,同时在移动应用UI控制方面也展现出强大潜力,为跨平台自动化提供了可能。
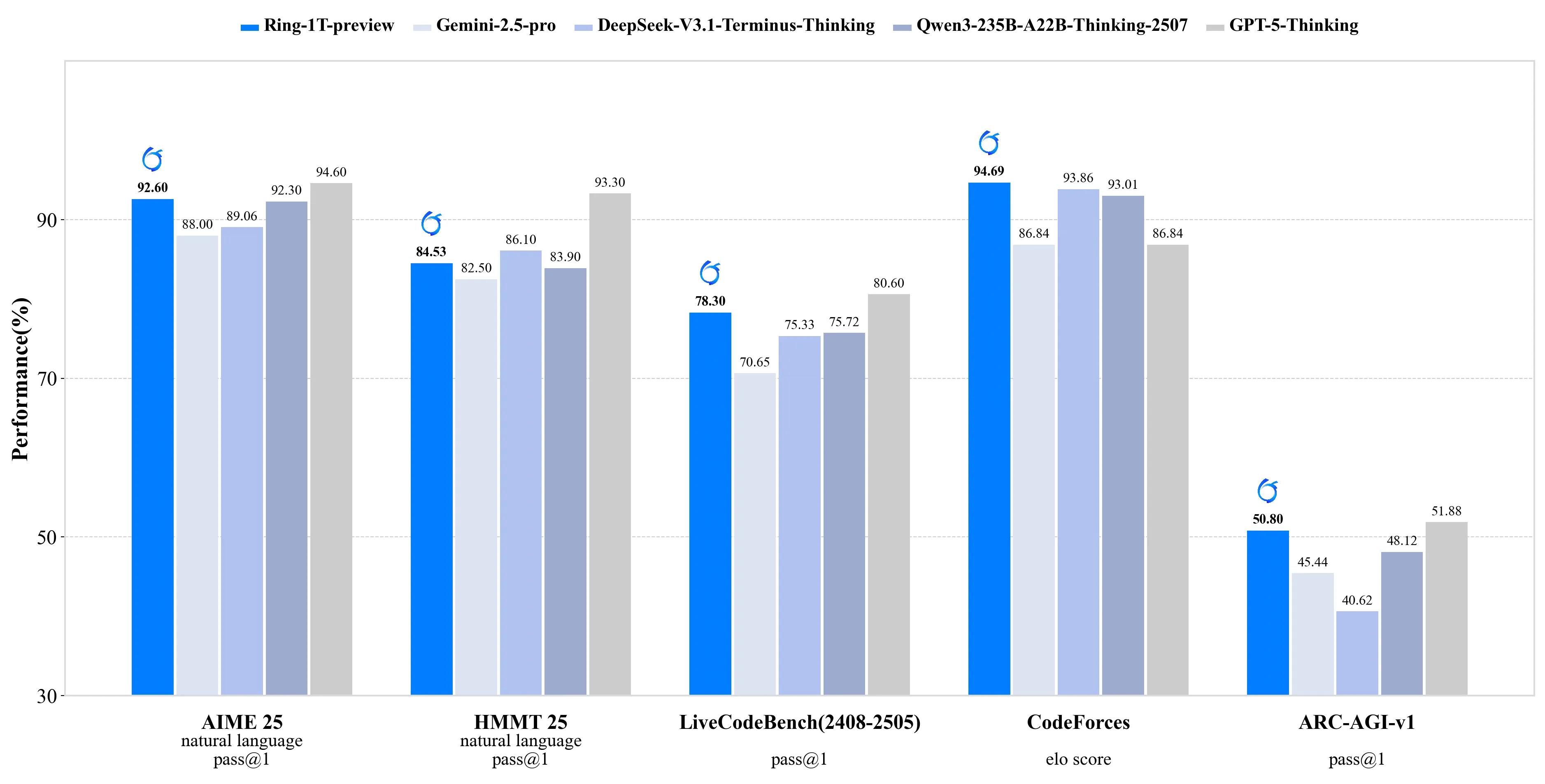
三、性能表现
Gemini 2.5计算机使用模型的性能并非空口无凭,其在多项权威的网页和移动控制基准测试中均展现了领先行业的实力。根据Google DeepMind自行运行、第三方评估机构Browserbase评估以及厂商自报告的综合数据,该模型在准确性上全面超越同类替代方案。
更为重要的是,它在实现高准确率的同时,还保持了极低的延迟。在处理复杂的Web任务时,响应速度相比其他方案有显著提升,这对于打造流畅、高效的自动化用户体验至关重要。Browserbase的评估报告特别指出,该模型在“Online-Mind2Web”测试中,以最低的延迟提供了顶级的任务完成质量。
四、安全架构与负责任部署
让一个AI模型自主操作计算机潜藏着独特风险,谷歌对此采取了多层次、深嵌入的安全防护策略。
1. 模型内嵌安全训练
该模型在训练阶段就学习了识别和拒绝有害、欺诈性或高风险的指令,其内在的安全设计是抵御风险的第一道防线。
2. 开发者安全控件
谷歌为开发者提供了强大的工具来定制智能体的行为准则:
- 每步安全服务(Per-step safety service):这是一个在模型之外的、推理时的安全校验服务。在模型输出一个动作后、客户端执行该动作前,此服务会对其进行了二次评估,拦截可能存在问题的操作。
- 系统指令(System instructions):开发者可以通过系统指令预先设定规则,要求智能体在遇到特定类型的操作(如涉及支付、修改系统设置、绕过安全验证等)时,必须拒绝执行或向用户请求明确确认,将最终控制权交还给人类。
这些措施共同构成了一个深度防御体系,旨在确保AI智能体在造福用户的同时,不会引入新的安全漏洞。谷歌也强烈建议开发者在部署前进行充分的测试。
五、实战应用与早期反馈
目前,该模型的能力已在多个真实场景中得到验证。
- 谷歌内部应用:谷歌支付平台团队将其用作 contingency 机制(应急方案),用于自动修复那些脆弱且经常失败的端到端UI测试。该模型能自主诊断测试失败的原因并执行修复操作,成功挽救了超过60%的失败测试执行,将原本需要数天的人工修复工作自动化。
- 早期访问用户:来自初创公司Poke.com的反馈显示,该模型在他们需要与人类设计的界面进行快速交互的iMessage和WhatsApp工作流中,性能比次优方案快50%。另一家专注于构建自主AI代理的公司Autotab则表示,该模型在复杂场景下的上下文解析可靠性极佳,使其在最困难的评估中性能提升了18%。
这些案例表明,该模型在个人助手、工作流自动化、UI测试等领域拥有 immediate 且强大的应用潜力。
六、如何开始使用
从即日起,任何开发者都可以开始体验和构建基于Gemini 2.5计算机使用模型的智能体。
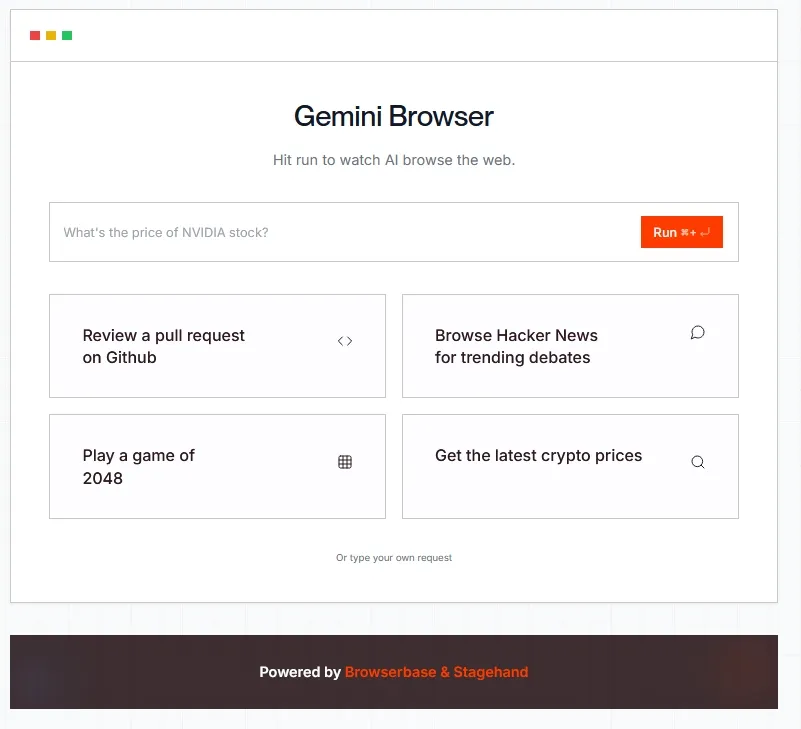
- 立即体验:您可以通过合作伙伴Browserbase提供的https://gemini.browserbase.com/ 直接体验模型的能力。
- 开始开发:正式的API已通过Google AI Studio和Vertex AI平台提供。开发者可以参考官方文档,学习如何在本地使用Playwright或在云端使用Browserbase的VM来构建自己的智能体循环。
- 加入社区:谷歌鼓励开发者前往https://developers.google.com/ 分享构建成果、提供反馈,共同塑造该技术的未来路线图。
七、访问地址
您可以访问https://makersuite.google.com/ 或 https://cloud.google.com/vertex-ai 平台获取API访问权限并查看详细技术文档。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章


暂无评论...