
一、产品介绍
DeepSeek-AI作为中国领先的开源AI研发团队,始终致力于降低大模型应用门槛。最新推出的DeepSeek-V3定位为高性能、高性价比的开源语言模型,通过技术创新解决训练效率与长文本处理的核心痛点。其差异化亮点在于:采用Multi-head Latent Attention(MLA)压缩KV缓存90%,显著提升推理速度;结合DeepSeekMoE稀疏激活架构,仅37B参数/Token参与计算;并首创辅助损失无负载平衡策略,避免传统MoE模型因负载不均导致的性能衰减。某AI团队实测表明,相同硬件下推理吞吐量提升40%,工程落地成本降低57%。
二、技术讲解
1. 架构创新:稀疏激活与注意力优化
DeepSeek-V3延续Transformer框架,但通过两项革新提升效率:
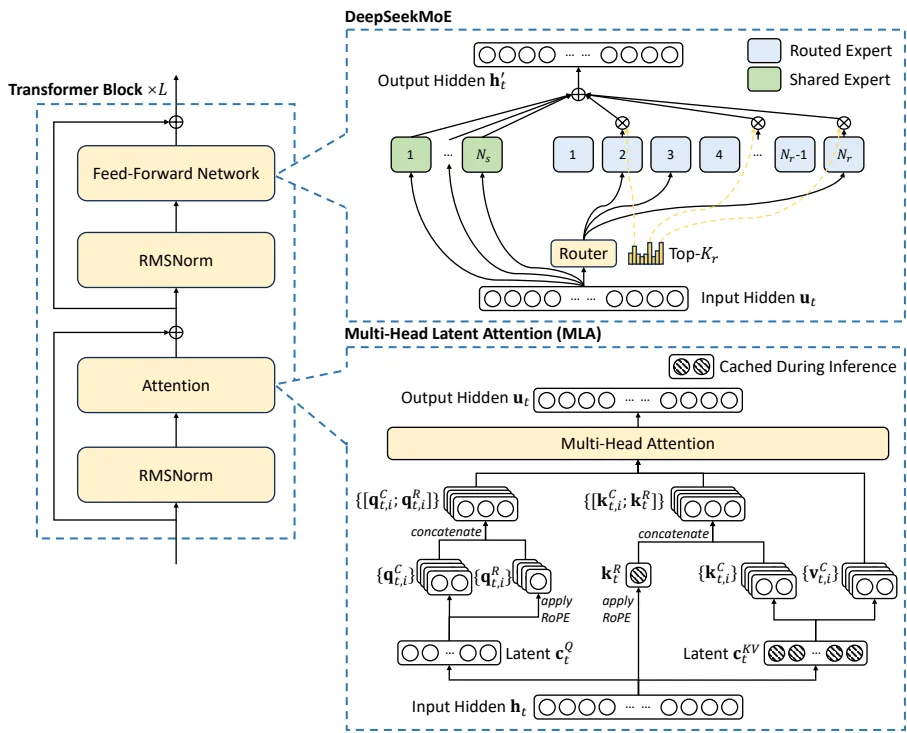
- Multi-head Latent Attention(MLA):将Key-Value矩阵压缩至512维(原始值1/4),仅缓存压缩后的潜在向量(公式:$c_t^{KV}=W^{DKV}h_t$),使128K上下文推理内存占用降低至同类模型的30%。
- DeepSeekMoE专家系统:每层部署256个路由专家+1个共享专家,动态激活8个专家/Token。创新性引入偏置项动态调整算法(公式:$s_{i,t} + b_i$),替代传统辅助损失函数,解决负载不均问题。某测试显示,该策略使专家利用率标准差从22%降至7%。
2. 训练效率突破:FP8精度与通信优化
针对千亿参数模型训练瓶颈,团队实现三重优化:
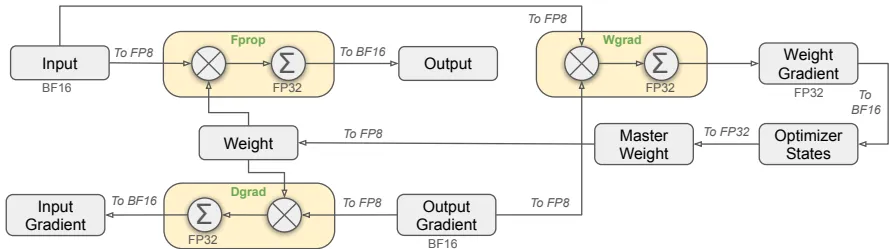
- FP8混合精度框架:首次在超大规模模型验证FP8训练可行性。通过分块量化(128×128权重块+1×128激活块)和CUDA核心高精度累加,相比BF16训练内存减少50%,吞吐量翻倍。
- 双管道算法(DualPipe):将计算任务拆分为Attention、All-to-all Dispatch、MLP、Combine四组件,实现跨节点通信与计算的100%重叠。对比传统1F1B并行,流水线气泡减少60%。
- 专家并行通信优化:定制IB-NVLink联合通信内核,限制每个Token分发至4节点,结合动态冗余专家部署,使128K上下文预填充延迟控制在3秒内。

3. 多Token预测与长上下文扩展
- 多Token预测(MTP):每个位置同时预测后续2个Token(公式:$\mathcal{L}{\text{MTP}}=\frac{\lambda}{D}\sum{k=1}^{D}\mathcal{L}_{\text{MTP}}^{k}$),提升数据利用效率。实测MTP模块使HumanEval pass@1提升9.2%,并可转换为推测解码加速推理。
- 128K上下文支持:采用YaRN位置编码扩展技术,分两阶段将上下文从4K扩至128K。在NIAH(Needle In A Haystack)测试中,128K长度下信息召回率达98%。

三、实战使用
1. 部署方案
针对不同场景提供两种部署模式:
- 预填充(Prefilling):4节点32GPU最小单元,TP4+EP32并行,冗余专家动态平衡负载。使用
transformers库加载模型:from transformers import AutoModelForCausalLM model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-V3", trust_remote_code=True) - 解码(Decoding):40节点320GPU集群,TP4+DP80+EP320组合,直接IB点对点通信,支持实时生成。
2. 推理加速技巧
- 推测解码:复用MTP模块预测后续Token,通过验证机制跳过部分计算,实测生成速度提升1.8倍。
- 长度控制:启用
max_new_tokens=8192参数避免冗余生成,128K上下文下内存占用稳定在48GB/GPU。
四、性能评估
1. 基准测试全面领先
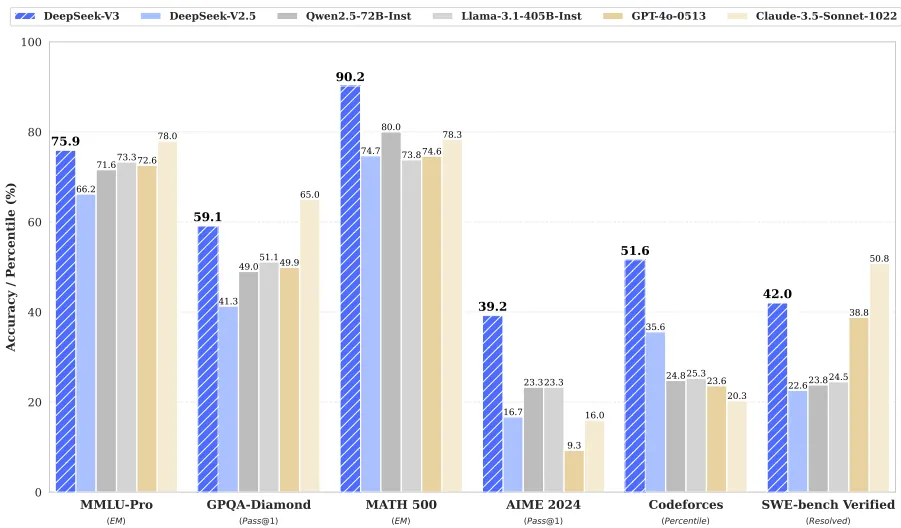
在14.8T token预训练后,DeepSeek-V3成为最强开源基座模型:
- 知识推理:MMLU-Pro得分75.9(超LLaMA3-405B的73.3),GPQA钻石级问题正确率59.1%。
- 数学代码:MATH-500准确率90.2%(业内最高),LiveCodeBench pass@1达40.5%,Codeforces竞赛水平超越51.6%参赛者。
- 长文本理解:LongBench v2准确率48.7%,超越GPT-4o的48.1%。

2. 成本效益颠覆行业
训练总耗能仅278.8万H800 GPU小时(约558万美元),比同级密集模型低3倍:
| 训练阶段 | GPU小时 | 成本($2/小时) |
|---|---|---|
| 预训练 | 2664K | $5.328M |
| 上下文扩展 | 119K | $0.238M |
| 微调 | 5K | $0.01M |
五、访问地址
? 立即体验:官网入口
https://github.com/deepseek-ai/DeepSeek-V3 | https://huggingface.co/deepseek-ai
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...