一、产品介绍
谷歌研究(Google Research)与谷歌DeepMind(Google DeepMind)联合团队致力于通过人工智能推动科学进步。本次推出的AI系统,其核心定位是解决科学研究中的一个根本性瓶颈:为计算实验手动创建专用软件的缓慢且繁复的过程。
该系统的差异化技术亮点在于,它并非一个简单的代码补全或生成工具,而是一个集成了大型语言模型(LLM)的智能代码突变系统,并辅以树搜索(Tree Search)算法进行系统性的探索和优化。其目标是全自动地创建所谓的“经验软件”(Empirical Software),即那些旨在最大化某个可定义、可衡量的质量分数(如预测准确性、积分精度、图像分割重合度)的软件程序。它将科学软件创作转化为一个“可评分任务”(Scorable Task)。
二、技术讲解
该系统的核心工作机制是一个由树搜索驱动的迭代优化循环,其算法核心可简要概括为以下几个步骤:
- 初始化:系统接收任务描述、评估指标、相关数据以及可选的“研究想法”(来自文献或搜索工具)。
- 代码生成与执行:LLM根据当前提示(包含已有代码和指令)生成新的候选Python代码。
- 评分:生成的代码在一个沙盒环境中被执行,其输出结果根据预定义的质量分数(如预测误差的倒数)进行评估。
- 树搜索与选择:系统采用一种改进的PUCT(Predictor+Upper Confidence bound applied to Trees)算法来管理搜索树。每个节点代表一个代码版本及其分数。算法会权衡利用(exploitation)(选择当前高分节点进行细化)和探索(exploration)(尝试新的、可能带来突破的方向),选择下一个要扩展的节点。
- 迭代优化:步骤2-4不断重复,LLM持续重写和改进代码,树搜索智能地引导整个探索过程,朝着更高分数的方向前进,直至达到满意结果或计算资源耗尽。
这种方法与传统方法的关键区别在于:
- vs. 遗传编程(GP):不同于GP的随机变异和交叉,本系统使用LLM进行语义感知的代码重写,能产生更复杂、更有意义的变异。
- vs. 自动化机器学习(AutoML):AutoML主要搜索模型架构和超参数,而本系统可以生成和优化任何类型的软件,包括数据预处理、复杂模拟和数学启发式算法,范围更广。
- vs. 一次性代码生成:它不是一个单次生成模型,而是一个持续的、目标驱动的优化过程。
研究想法的整合是另一大创新。用户或AI辅助搜索工具(如Gemini Deep Research)可以提供来自顶尖论文、教科书的研究思路。LLM能够理解这些自然语言描述,并将其作为高级指令融入代码生成过程中,从而实现“在巨人的肩膀上”进行创新。
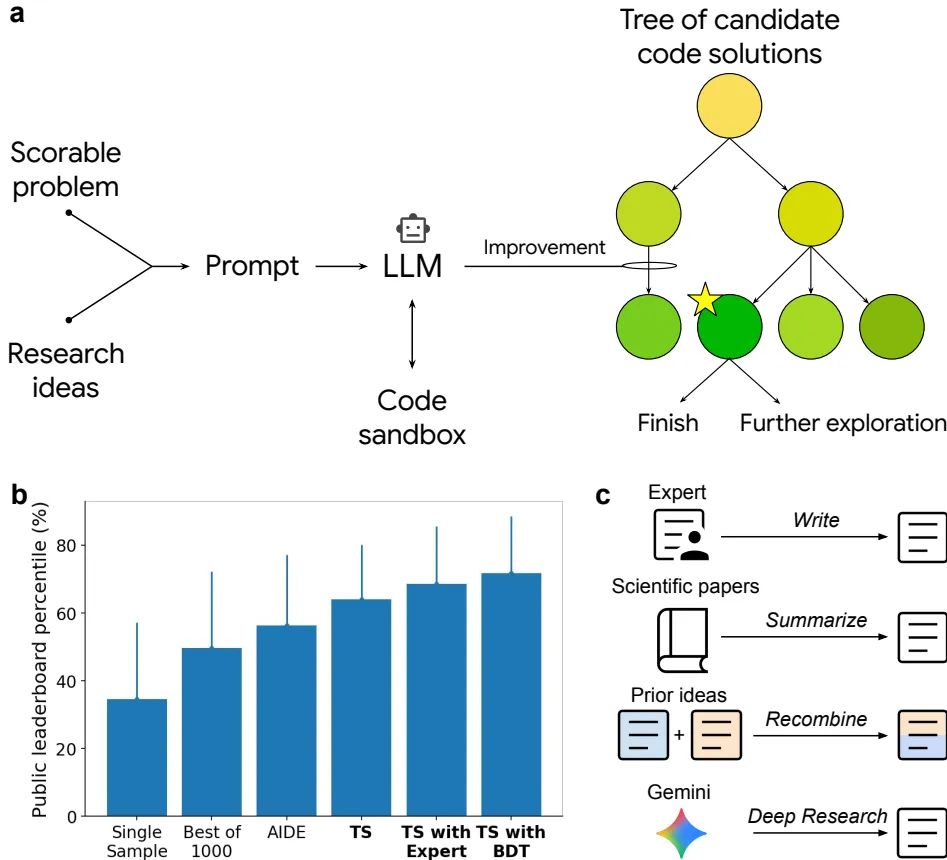
图1 | 方法示意图与在Kaggle基准测试上的性能。(a)方法算法示意图。(b)在16个任务上的平均公开排行榜百分位性能。基于本方法的策略以粗体显示。(c)用于解决科学问题的初始研究想法的生成机制。
三、实战使用与性能表现
研究团队在多个科学领域的公开基准上对该系统进行了 rigorous(严格)测试,结果显著。
1. 生物信息学:scRNA-seq数据批处理整合
单细胞RNA测序(scRNA-seq)技术能解析细胞异质性,但整合不同实验室产生的数据集时,去除批次效应是一大挑战。OpenProblems基准评估了15种最先进的方法。
- 过程:系统在单独的数据集上进行训练和优化,最终在OpenProblems的保留测试集(包含1,747,937个细胞)上评估性能。
- 结果:仅使用树搜索(无额外指导)生成的解决方案,其概念类似于ComBat算法,但性能已优于当前排行榜。当提供现有顶尖方法的论文摘要作为提示时,系统生成的代码在9种方法中的8种上超越了其对应的人类发表成果。其中,最顶尖的方案BBKNN(TS)实现了14%的整体性能提升(相较于最佳已发表方法ComBat)。
- 创新点:系统自动发现了将ComBat与BBKNN方法结合的创新方案(在ComBat校正后的PCA嵌入上计算邻居),手动实验证实这种组合是性能提升的关键。
- 规模化探索:系统进一步进行了“重组”实验,将不同方法的思路两两组合,生成了55个新想法。其中44%的重组解决方案性能超过了它们的两个“父方法”。最终,该系统共产生了40种性能超过OpenProblems排行榜上所有已发表方法的新方案。
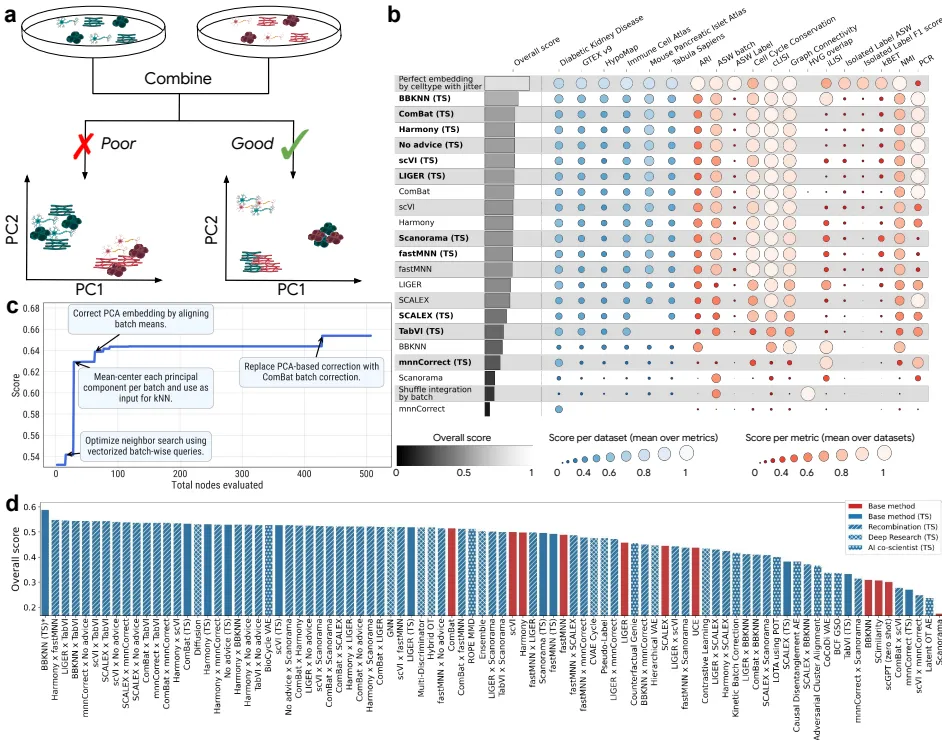
图2 | 树搜索在scRNA-seq批处理整合上的性能。(b)本方法(粗体,后缀“(TS)”)与对应已发表方法在OpenProblems基准上的性能对比。(c)顶级方案BBKNN的性能改进与代码创新。(d)OpenProblems基准上所有非控制方法的整体分数,包括本方法生成的各种方案。
2. 公共卫生:COVID-19住院人数预测
该系统在美国疾控中心(CDC)协调的COVID-19 Forecast Hub(CovidHub)上进行了测试,该平台汇聚了数十个顶尖团队的预测模型。
- 过程:采用滚动验证窗口,使用过去6周的数据进行模型优化和选择,并对2024-2025季度的数据进行预测。
- 结果:最终产生的“Google Retrospective”模型平均加权区间分数(WIS,越低越好)为26,优于官方新冠预测中心集合(CovidHub-ensemble)的29,且在大多数州的表现都更好。
- 复制与重组:系统仅根据其他团队提交的简短公开描述,成功复制了8个现有模型,其中6个复现版本的性能超过了原版提交。更重要的是,通过将不同模型的思路进行两两重组,生成了28个混合模型,其中11个混合模型的性能优于其两个父模型。总计,系统探索出的14种策略的性能超过了官方新冠预测中心集合。
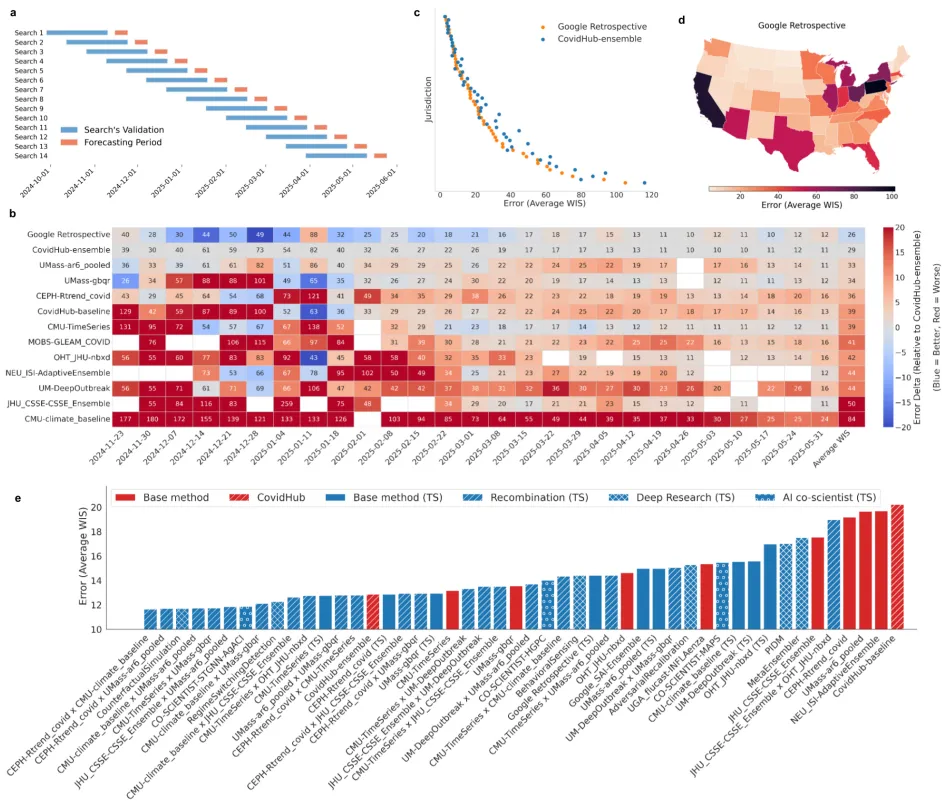
图3 | 树搜索在COVID-19预测上的性能。(b)时间序列排行榜显示各参与团队及本模型每周的预测性能。(c)本模型与CovidHub-ensemble在各州的直接对比。(d)本模型预测误差的地理分布。(e)各种建模策略的聚合预测性能对比。
3. 其他领域表现
- 地理空间分析:在DLRSD遥感图像语义分割任务中,系统生成的三个顶级解决方案的mIoU(平均交并比)均超过了0.80,超越了近期的学术论文结果。
- 神经科学:在ZAPBench全脑神经活动预测基准上,系统生成的解决方案在所有预测步长(除1步外)上均优于所有时间序列基线以及最佳的视频模型,且训练速度快数个数量级。
- 时间序列预测:在GIFT-Eval基准测试中,系统为每个数据集单独寻找的解决方案性能超过了2025年5月18日的排行榜冠军。此外,系统还成功创建了一个统一的、通用的预测库,仅使用基础库(如numpy, pandas)即在所有数据集上取得了高度竞争力表现。
- 数值分析:系统成功构建了一个优于标准
scipy.integrate.quad()的通用数值积分库。在一个包含38个quad()无法正确求解的振荡积分测试集上,进化后的代码在19个保留测试积分中正确求解了17个,而quad()在所有案例中均失败。
| 方法 | 年份 | 架构类型 | 关键特征/技术 | mIoU |
|---|---|---|---|---|
| Solution 1(TS) | 2025 | CNN(UNet++) | ‘efficientnet-b7’编码器,8倍TTA | 0.81 |
| Solution 2(TS) | 2025 | Transformer(SegFormer) | ‘mit-b1’编码器,4倍TTA | 0.82 |
| Solution 3(TS) | 2025 | CNN(U-Net) | ‘se_resnext101_32x4d’编码器,7倍TTA | 0.80 |
| RE-Net | 2021 | CNN(基于区域) | 区域上下文学习 | 0.762 |
| FURSformer | 2023 | CNN+Transformer | 自定义融合模块 | 0.753 |
| SCGLU-Net | 2024 | CNN+Attention | 空间-通道-全局-局部块 | 0.666 |
表1 | 在DLRSD基准上的模型性能对比。显示本方法的解决方案(前三行)与近期学术论文方法的对比。
对比(越低越好).webp)
图4 | 在ZAPBench上,最佳树搜索解决方案与时间序列和视频预测方法的平均绝对误差(MAE)对比(越低越好)。
四、访问地址
关于该项目的更多细节,包括部分生成的解决方案代码和用于检查树搜索数据的用户界面,可在GitHub上获取:
https://github.com/google-research/score
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章


暂无评论...