一、产品介绍:改变游戏规则的评测平台
美国AI数据巨头Scale AI(服务OpenAI/谷歌/Meta的顶级数据供应商)于2024年推出SEAL评测平台(Safety, Evaluations, and Alignment Lab)。不同于传统公开数据集评测,该工具通过动态私有题库+领域专家审核,成为首个能有效防止模型作弊的工业级评估系统。其评测结果已被Anthropic、谷歌DeepMind等头部公司采纳为模型优化基准。
二、适用人群速查表
| 角色 | 应用场景 | 核心价值 |
|---|---|---|
| ? AI研究员 | 模型能力对比 | 获取无污染评测数据 |
| ?️ 算法工程师 | 模型迭代优化 | 定位能力短板 |
| ? 产品经理 | 技术选型决策 | 客观对比商业模型 |
| ? 安全工程师 | 风险漏洞检测 | 红队测试支持 |
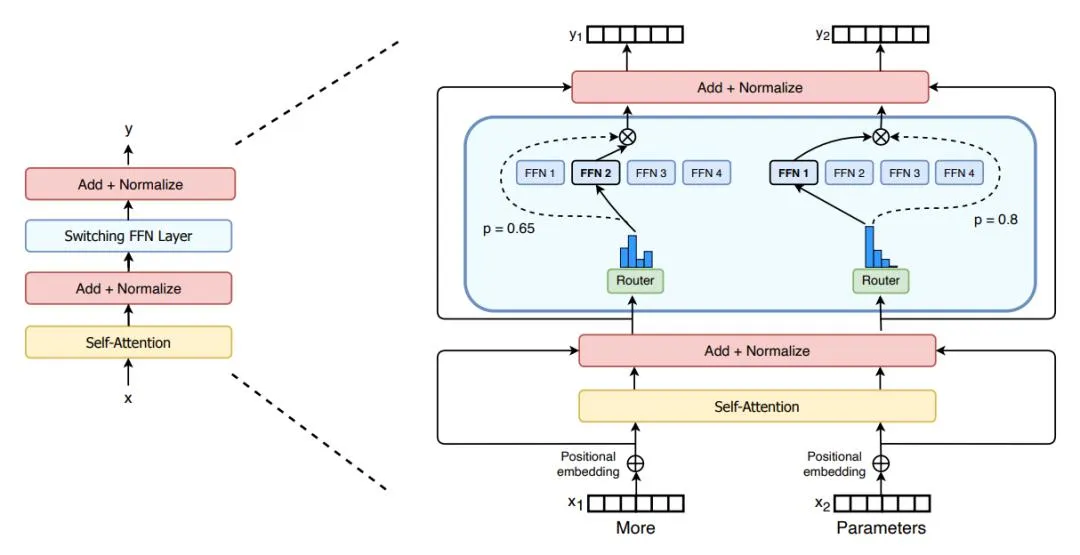
三、核心功能与技术原理
1. 防作弊私有数据集
- 技术实现:
动态生成未公开的测试题库(每月更新20%),涵盖代码生成/数学推理/多语言理解三大领域。采用对抗样本生成技术构建高难度案例,从根源杜绝模型过拟合。 - 案例:
代码评测集含1000+提示,覆盖调试/优化/文档生成等场景,远超HumanEval等传统数据集广度。
2. 专家人工评估机制
graph LR
A[模型输出] --> B{专家评审团}
B --> C[语言流畅度]
B --> D[事实准确性]
B --> E[逻辑完备性]
C --> F[综合评分]
D --> F
E --> F3. 多维度能力雷达图
支持生成6大能力可视化报告:
- 代码生成(Python/JS/Go等)
- 数学推理(定理证明/数值计算)
- 多语言处理(中/西/法/德等)
- 指令跟随
- 安全合规
- 知识检索
4. 动态竞赛环境
每月注入新数据集+新模型对比,例如:
- GPT-4 Turbo在代码测试以1155分领先
- Claude 3 Opus数学推理碾压全场
- Gemini 1.5多语言处理并列第一
5. 军事级安全评估(Defense版本)
针对国家安全领域定制:
- 战场决策模拟
- 威胁情报分析
- 武装冲突法合规检测
四、工具使用技巧
✅ 高效操作指南
聚焦短板优化
在数学板块得分低?使用子模块分析功能定位薄弱环节(如几何证明/概率计算)定制评估集
上传行业特定术语(如医疗/金融名词)构建垂直领域测试集竞品对比策略
同时提交多个模型输出,获取并排对比报告:| 模型 | 代码得分 | 数学得分 | 多语言得分 | |------|---------|---------|-----------| | GPT-4o | 1144 | 89.7 | 92.1 | | Claude 3 | 1102 | **95.3** | 88.9 |红队测试模式
激活安全检测模块,模拟200+种对抗攻击场景
五、访问地址
? 立即体验:
? https://scale.com/leaderboard
评测数据不会说谎,但可以被设计。当传统榜单陷入刷分困局时,SEAL用动态防火墙+人类智慧重新定义可信评估。
——AI评测领域迎来真正的「防作弊考场」
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...