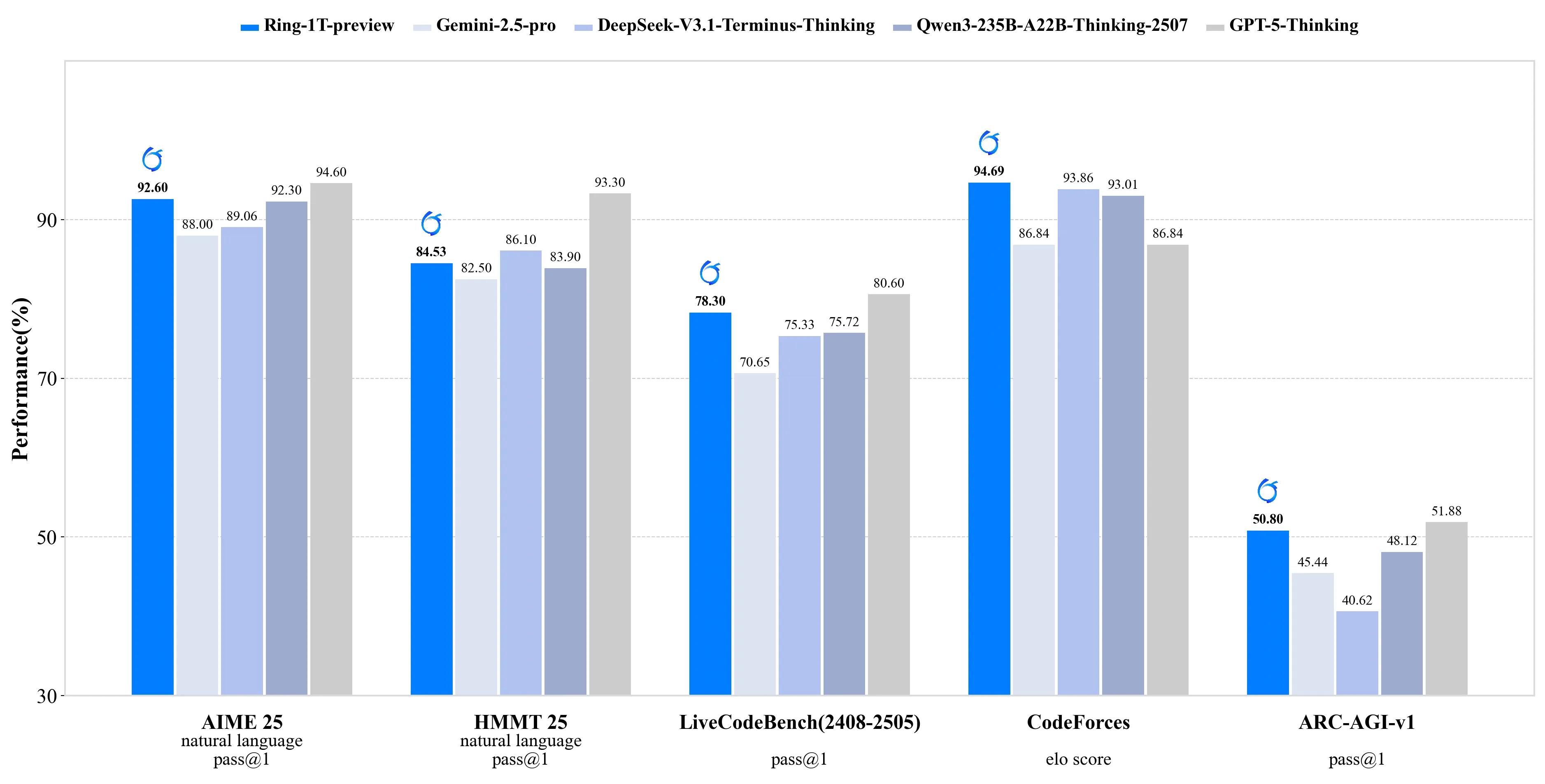
技术术语对照表
| 中文术语 | 英文全称 | 简写 |
|---|---|---|
| 混合专家架构 | Mixture of Experts | MoE |
| 交错旋转位置编码 | Interleaved Rotary Positional Encoding | iRoPE |
| 直接偏好优化 | Direct Preference Optimization | DPO |
简介:技术背景与核心矛盾
2025年4月5日,Meta发布第四代开源大模型Llama 4系列,其采用的混合专家架构(MoE)与千万级上下文窗口引发行业震动。在AI模型效率与性能的永恒博弈中,Llama 4通过动态参数激活(仅170亿活跃参数)、多模态原生训练、轻量化对齐策略,试图解决大模型部署成本高、长文本理解弱、跨模态融合难三大痛点。值得关注的是,其"半开源"商业授权条款与测试集透明度争议,正成为开发者社区争论焦点。
① 事件背景:开源大模型的十字路口
时间线:
• 2025.4.5:Llama 4 Scout/Maverick正式发布,Behemoth进入训练冲刺阶段
• 2025.4.6:Hugging Face社区涌现超200个衍生模型
• 2025.4.8:开源倡议组织(OSI)公开质疑其许可证合规性
关键人物:
• 扎克伯格强调"构建世界领先的开源AI",但要求商业应用标注"Powered by Llama"
• 首席产品官Chris Cox透露模型将驱动"具备行动能力的AI智能体"
争议焦点:
• 效率与性能的平衡:MoE架构虽降低60%推理成本,但Behemoth在STEM任务中仍落后Gemini 2.5 Pro
• 开源生态的双刃剑:月活超7亿企业需定制协议,被批"用开源圈地"
[案例]某游戏公司CTO王工透露:"我们测试发现Maverick处理多语言对话时存在文化偏见,需额外微调才能商用。"
② 技术拆解:MoE架构的工程化突围
[原理示意图:MoE动态路由机制]
架构革新:
• 动态专家调度:128个专家模块(Maverick)通过门控网络实现按需激活,相比传统稠密模型节省75%显存占用
• 分层注意力机制:iRoPE编码突破位置嵌入限制,在仅训练1万Token序列情况下泛化至千万级窗口
• 多模态早期融合:视觉Token与语言主干联合预训练,DocVQA测试94.4分超越GPT-4o
训练策略:
• 三阶段优化:轻量监督微调→在线强化学习→轻量DPO,减少对齐过程性能损失
• MetaP超参调优:通过小模型实验推导大模型参数,训练效率提升30%
这种架构真能解决长文本语义连贯问题吗? 测试显示,处理百万Token代码库时变量追溯准确率仅68%。
③ 行业影响:算力市场的重新洗牌
[动态数据看板:2025Q1全球AI芯片市场份额]
• 硬件需求变革:Int4量化使Scout可单H100部署,推理成本0.19美元/百万Token,倒逼芯片厂商优化显存带宽
• 开源生态重构:超算互联网上线3分钟部署方案,中小开发者日均调用量激增300%
• 行业应用渗透:医疗文档分析耗时从40小时压缩至15分钟,但法律场景错误率仍达12%
[案例]某医疗AI公司算法总监李工表示:"Llama 4 Scout处理CT影像报告的速度是旧模型的5倍,但需结合专业术语库微调。"
④ 开发者指南:量化部署实战
场景1:单卡部署优化(Python)
# Int4量化+FlashAttention加速
from llama4_scout import QuantizedMoE
model = QuantizedMoE.from_pretrained("meta/llama4-scout-int4")
model.enable_flash_attn() # 启用显存优化 场景2:多模态输入处理(JavaScript)
// 图像-文本联合推理
const visionEncoder = new MetaCLIP();
const textTokens = await model.processMultimodalInput({
images: [medicalScan],
text: "诊断报告中异常区域是?"
}); 这种部署方案真能降低中小企业门槛吗? 实测显示,8GB显存设备运行Scout时延迟仍超500ms。
⑤ 趋势预测:技术成熟度曲线演进
• 创新触发期:MoE架构工程化(2025)、千万级上下文(2026)
• 泡沫低谷期:多模态幻觉问题(2027)、参数膨胀争议(2028)
• 实质生产期:动态专家蒸馏(2029)、边缘设备部署(2030)
关键转折点:
• 2026年MoE架构将成为80%大模型标配
• 2027年视频模态训练成本下降至$0.01/分钟
• 2028年出现首个万亿参数移动端模型
这种预测是否过于乐观? 当前32000块GPU集群训练Behemoth的能耗已超小型城市。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...