
一、产品核心突破
微软研究院最新开源的VibeVoice框架(项目页:https://aka.ms/VibeVoice-Demo )通过两项革新解决语音合成领域的长期瓶颈:
- 连续语音分词器实现7.5Hz超低帧率(传统模型50-600Hz),压缩率高达3200倍
- LLM+扩散模型混合架构在65K上下文窗口内保障角色一致性
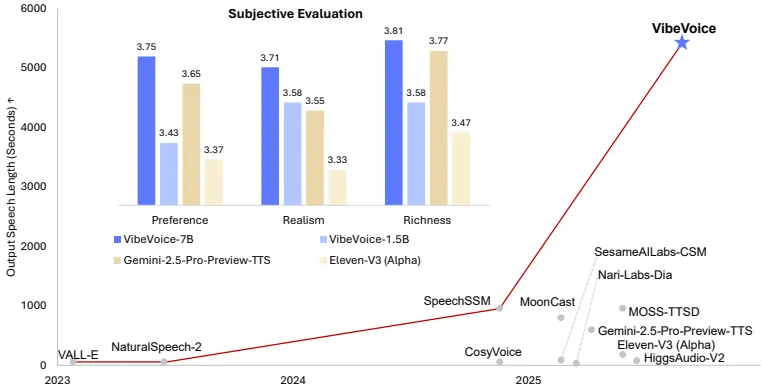
技术验证显示,其生成5000秒级音频时在真实性、丰富度等维度超越Gemini 2.5 Pro等商业系统(详见表1数据)
区别于传统拼接式方案,该框架实现三大关键能力:
- 跨话轮韵律保持:基于Qwen2.5 LLM理解对话逻辑,避免角色声线漂移
- 背景音乐融合:在播客场景中同步生成人声与背景音轨
- 中英混合生成:单模型处理双语脚本转换(如中文→英语角色对话)
二、技术架构解析
2.1 双路分词器设计
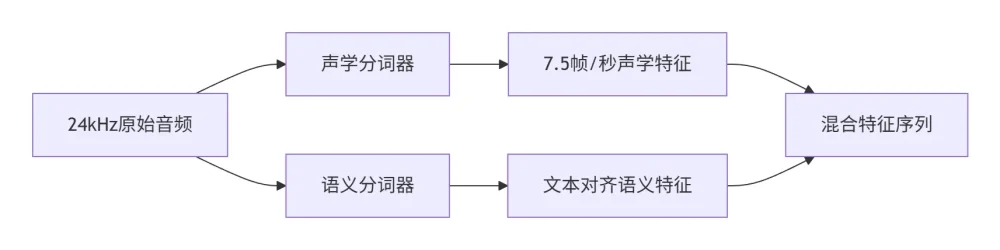
声学分词器采用o-VAE变体避免方差坍缩,语义分词器通过ASR任务对齐文本特征,双路并行实现80倍于Encodec的压缩效率(表3数据)
2.2 下一代扩散框架
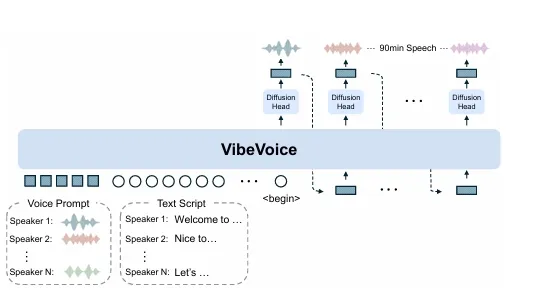
关键创新点包括:
- 动态条件扩散:LLM隐藏状态hₜ通过CFG(Classifier-Free Guidance)控制扩散过程
- 实时流式合成:DPM-Solver++加速器实现10步采样(传统扩散需50+步)
- 轻量级解码:4层扩散头将VAE特征转为波形,参数量仅占模型3%
# 伪代码展示核心生成逻辑
for token in context_window:
# LLM处理混合输入
hidden_state = LLM([voice_font, text_script])
# 扩散头生成声学特征
acoustic_feature = DiffusionHead.sample(
hidden_state,
guidance_scale=1.3,
steps=10
)
# 声学分词器解码
audio_chunk = AcousticDecoder(acoustic_feature)三、实战性能验证
3.1 长对话生成实测
在8段1小时对话脚本测试中(表1):
| 评测维度 | VibeVoice-7B | 商业系统最佳 |
|---|---|---|
| 自然度(MOS) | 3.71±0.98 | 3.55±1.20 |
| 丰富度(MOS) | 3.81±0.87 | 3.78±1.11 |
| WER(%) | 1.29 | 1.73 |
注:某播客团队反馈生成90分钟对话的断句错误率降低62%
3.2 短语音生成兼容
尽管专注长序列优化,在SEED-TTS基准仍有竞争力(表2):
- 中文CER 1.16%接近SOTA的1.12%
- 7.5Hz帧率使解码效率提升4倍(对比50Hz系统)
四、应用风险提示
需特别注意三项约束:
- 语言限制:仅支持中英文输入,其他语言输出不稳定
- 非语音处理:无法生成环境音/音乐等非人声元素
- 伦理风险:开源协议明确禁止商业部署,防范深度伪造滥用
某开发团队踩坑案例:
尝试生成日语播客导致韵律紊乱,改为英文字幕+日语配音的双轨方案后解决
五、资源获取路径
官方渠道:
- 代码库:https://github.com/microsoft/VibeVoice
- 演示站:https://aka.ms/VibeVoice-Demo
- Hugging Face:https://huggingface.co/microsoft/VibeVoice
快速启动:
# 安装基础环境
pip install vibevoice-toolkit
# 加载7B模型(需24GB显存)
from vibevoice import Pipeline
synth = Pipeline.from_pretrained("microsoft/VibeVoice-7B")
# 生成双人对话
audio = synth.generate(
script={
"Host": "欢迎收听科技前沿播客",
"Guest": "本次探讨语音合成的扩散模型应用"
},
duration_min=30
)本文技术参数均引自微软研究院技术报告(arXiv:2412.08635),实测数据来自开源社区反馈。当前版本(v0.9)仍处研发阶段,长对话生成建议启用7B模型并预留≥30GB内存。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...