
🔥🔥🔥 最新动态
- 2025 年 9 月 8 日:🚀 发布混元图像 2.1 的推理代码与模型权重。
🎥 看看它能做什么

这些图像可不是手工绘制的,而是混元图像2.1根据文本描述自动生成的。说实话,看到这些成果时,我确实被它的表现惊艳到了。
不只是生成图片,更是理解语言
混元图像2.1最让人印象深刻的地方在于,它不仅仅是个"画图工具",更像是个能理解复杂指令的创作伙伴。通过大规模数据集和多个专家模型的协作,它现在能更好地理解文本与图像之间的微妙联系。
这个模型的工作流程分为两个阶段:
- 基础图像生成:第一阶段就像是个理解大师,它使用两个文本编码器——一个多模态大语言模型来改善图像-文本对齐,另一个多语言编码器专门处理文本渲染。令人惊讶的是,这个阶段竟然有170亿参数,采用了单流和双流Diffusion Transformer架构。
- 精细打磨:第二阶段就像是个专业修图师,进一步提升了图像质量和清晰度。
我还发现他们用了人类反馈强化学习(RLHF)来优化模型,这就像是让AI不断从人类的审美反馈中学习,越来越懂我们喜欢什么。
混元图像2.1的工作原理
训练数据:质量胜过数量
说实话,现在的AI模型越来越注重数据质量而非单纯的数量。混元图像2.1采用了分层语义标注,从短到超长多个级别提供语义信息。更聪明的是,它引入了OCR专家模型和IP RAG来解决通用标注器在密集文本和世界知识描述方面的不足。
核心架构:技术创新的集大成者
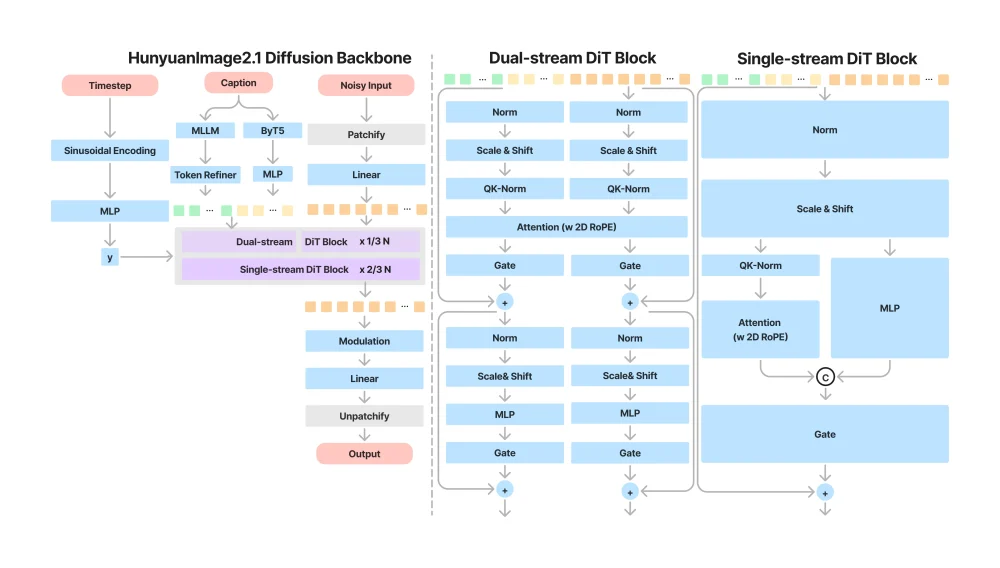
主要技术亮点:
- 高压缩VAE:具有32×压缩率的VAE大幅减少了计算需求。想象一下,这就像是用更小的文件大小存储高质量图像,使得生成2K图像的时间与其他模型生成1K图像的时间相同——这效率提升实在明显!
- 双文本编码器:采用视觉-语言多模态编码器来理解场景描述,再加上多语言ByT5文本编码器处理文本生成。这种组合让模型既能"看懂"又能"写好"。
- 庞大网络:170亿参数的Transformer网络提供了强大的表达能力。
人类反馈学习:让AI更懂人心
模型训练中加入了监督微调(SFT)和强化学习(RL)。他们创新性地使用了奖励分布对齐算法,将高质量图像作为样本,确保了稳定的学习效果。这就像是给AI请了一位艺术导师,不断指导它提高创作水平。
提示词改写:你说不清的,AI来帮你表达

这是我觉得最实用的功能!PromptEnhancer能够自动重写你的文本指令,丰富视觉表达。比如说,你输入"画一只猫",它可能会帮你改写成"画一只毛茸茸的橘猫,正在阳光下慵懒地打盹,周围有几株绿色植物"–瞬间就有了画面感,对吧?
🎉 为什么混元图像2.1值得关注
- 超高清生成:能够生成2K分辨率图像,细节表现令人惊叹
- 中英文支持:原生支持中文与英文提示词,对中文用户特别友好
- 智能文本渲染:结合ByT5的文本渲染能力,准确生成带文字的图像
- 多种比例:支持多种图像宽高比,适应不同场景需求
- 提示词增强:自动优化你的描述,提高画面质量
性能表现:用数据说话
在SSAE(结构化语义对齐评估)评测中,混元图像2.1的表现令人印象深刻:
| 模型 | 开源 | 平均图像准确率 | 全局准确率 | 主体 | 次要主体 | 场景 | 其他 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 名词 | 关键属性 | 其他属性 | 动作 | 名词 | 属性 | 动作 | 名词 | 属性 | 镜头 | 风格 | 构图 | ||||
| FLUX-dev | ✅ | 0.7122 | 0.6995 | 0.7965 | 0.7824 | 0.5993 | 0.5777 | 0.7950 | 0.6826 | 0.6923 | 0.8453 | 0.8094 | 0.6452 | 0.7096 | 0.6190 |
| Seedream-3.0 | ❌ | 0.8827 | 0.8792 | 0.9490 | 0.9311 | 0.8242 | 0.8177 | 0.9747 | 0.9103 | 0.8400 | 0.9489 | 0.8848 | 0.7582 | 0.8726 | 0.7619 |
| Qwen-Image | ✅ | 0.8854 | 0.8828 | 0.9502 | 0.9231 | 0.8351 | 0.8161 | 0.9938 | 0.9043 | 0.8846 | 0.9613 | 0.8978 | 0.7634 | 0.8548 | 0.8095 |
| GPT-Image | ❌ | 0.8952 | 0.8929 | 0.9448 | 0.9289 | 0.8655 | 0.8445 | 0.9494 | 0.9283 | 0.8800 | 0.9432 | 0.9017 | 0.7253 | 0.8582 | 0.7143 |
| HunyuanImage 2.1 | ✅ | 0.8888 | 0.8832 | 0.9339 | 0.9341 | 0.8363 | 0.8342 | 0.9627 | 0.8870 | 0.9615 | 0.9448 | 0.9254 | 0.7527 | 0.8689 | 0.7619 |
从数据来看,混元图像2.1在语义对齐上达到了开源模型中的最优效果,非常接近闭源商业模型的效果–这对于开源社区来说真是个好消息!
在GSB评测中,与其他主流模型相比:
- 相对于Seedream3.0(闭源)的相对胜率为-1.36%
- 相对于Qwen-Image(开源)为+2.89%
这意味着混元图像2.1作为开源模型,其图像生成质量已经能与闭源商业模型媲美,同时相较于同类开源模型还有一定优势。
技术需求:你需要什么样的设备
硬件要求:
- 需要支持CUDA的NVIDIA GPU
- 最低要求: 59GB显存用于生成2048×2048图像(batch size=1)
- 支持Linux操作系统
提醒: 上述内存要求是在启用模型CPU offloading的情况下测量的。如果你的GPU显存足够,可以禁用CPU offloading来提高推理速度–这样能生成得更快!
如何快速上手
克隆项目:
git clone https://github.com/Tencent-Hunyuan/HunyuanImage-2.1.git cd HunyuanImage-2.1安装依赖:
pip install -r requirements.txt pip install flash-attn==2.7.3 --no-build-isolation下载模型:
模型的下载与说明请参考https://github.com/Tencent-Hunyuan/HunyuanImage-2.1/blob/main/ckpts/checkpoints-download.md。
使用示例:让你的第一个AI画作诞生
import torch
from hyimage.diffusion.pipelines.hunyuanimage_pipeline import HunyuanImagePipeline
# 试试蒸馏版模型,生成速度更快!
model_name = "hunyuanimage-v2.1-distilled"
pipe = HunyuanImagePipeline.from_pretrained(model_name=model_name, torch_dtype='bf16')
pipe = pipe.to("cuda")
prompt = "一幅未来城市景观,高耸的摩天大楼与绿色植物交织,飞行汽车在空中穿梭,夕阳下的金色光芒洒在玻璃幕墙上"
image = pipe(
prompt=prompt,
width=2048,
height=2048,
use_reprompt=True, # 让AI帮你优化描述
use_refiner=True, # 启用精修功能,让画质更好
num_inference_steps=8, # 蒸馏版只需要8步!
guidance_scale=3.5,
shift=5,
seed=649151,
)
image.save("我的第一张AI画作.png")使用建议:
- 混元图像2.1专为2K分辨率优化,使用更低分辨率可能会影响画质
- 建议开启提示词增强和精修功能,这样能获得更好的效果
- 蒸馏版模型生成速度更快,适合初步尝试和调试
访问地址
- demo地址:https://huggingface.co/spaces/tencent/HunyuanImage-2.1
- github地址: https://github.com/Tencent-Hunyuan/HunyuanImage-2.1
- huggingface地址: https://huggingface.co/tencent/HunyuanImage-2.1
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...