
一、产品介绍
群核科技(Manycore Research)作为3D视觉计算领域的创新者,近期开源了SpatialGen-1.0——首个支持语义布局到多模态3D场景的生成式模型。该模型通过多视角扩散架构,实现了从单张设计草图或文本描述到可交互3D场景的端到端生成,解决了传统工作流中建模周期长、多软件协作效率低的痛点。
技术差异化亮点:
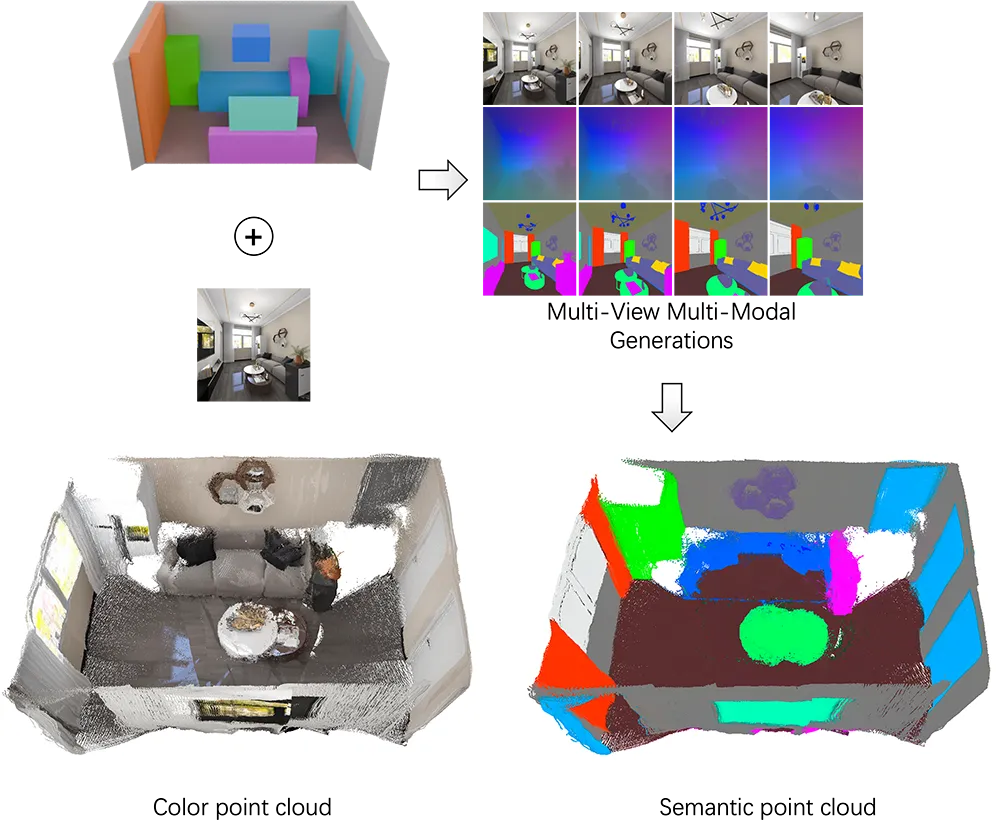
- ? 跨模态对齐:同步生成RGB图像、法线贴图、深度图及语义分割图(如图1)
- ? 布局约束优化:基于SpatialLM的语义理解技术确保空间逻辑一致性
- ⚡️ 分布式推理加速:集成DiffSplat渲染引擎,推理速度较传统方案提升200%
二、技术讲解
2.1 核心架构
SpatialGen采用级联扩散模型(Cascaded Diffusion Pipeline):
- 语义编码层:将输入图像/文本编码为3D布局向量
- 多视角扩散模块:基于Stable Diffusion 2.1微调,并行生成100+视角数据
- 跨模态融合器:通过TAESD技术实现四模态数据空间对齐
2.2 训练策略
- 数据集:SpatialGen-Testset含48个标准房间布局,覆盖住宅/商业场景
- 增强技术:采用Progressive Latent Distillation提升小样本泛化能力
- 损失函数:结合CLIP语义约束与LPIPS视觉保真度优化
# 典型推理流程(摘自官方脚本)
pipe = SpatialGenDiffusionPipeline.from_pretrained(
"manycore-research/SpatialGen-1.0",
torch_dtype=torch.float16
)
scene_data = pipe(
prompt="现代客厅,L形沙发,落地窗",
num_inference_steps=30,
output_type="multimodal" # 同时输出四模态数据
)三、实战使用
3.1 环境部署
硬件要求:NVIDIA GPU (≥24GB VRAM) + CUDA 12.1
# 创建虚拟环境(实测Python 3.10兼容性最佳)
git clone https://github.com/manycore-research/SpatialGen.git
cd SpatialGen
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt3.2 场景生成案例
案例1:图像转3D场景
# 输入布局图生成全景场景
bash scripts/infer_spatialgen_i2s.sh \
--input_img bedroom_layout.png \
--output_dir 3d_scene输出效果:生成100+视角的RGB/深度/法线序列,支持Blender直接导入
案例2:文本转交互场景
# 通过文本描述生成可交互场景
bash scripts/infer_spatialgen_t2s.sh \
--prompt "极简主义办公室,胡桃木书桌,弧形落地灯" \
--enable_vr # 启用WebGL交互模式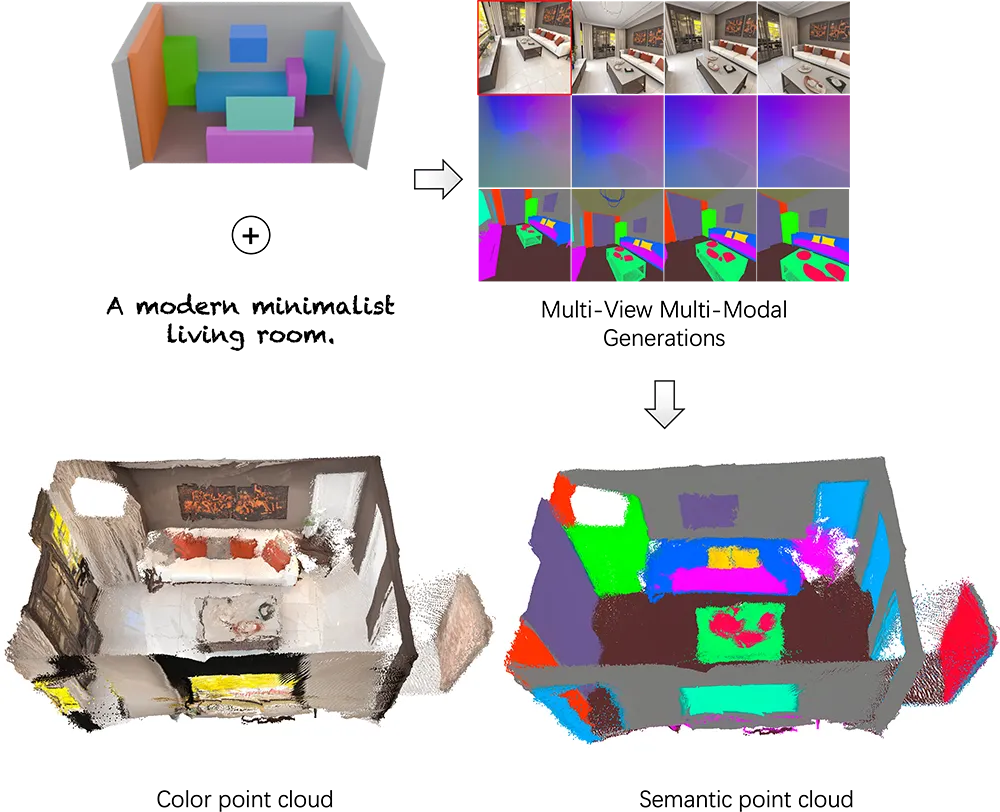
文本转交互场景
某设计团队实测:生成1个标准办公场景仅需8分钟,较传统工作流效率提升3倍
四、性能基准
| 任务类型 | 输入规格 | 输出分辨率 | 推理耗时 (A100) |
|---|---|---|---|
| 图像→3D场景 | 512×512布局图 | 1024×1024 | 5.2分钟 |
| 文本→3D场景 | 80字符描述 | 1024×1024 | 7.8分钟 |
| 交互式VR场景 | 4视角关键帧 | 全景360° | 3.1分钟 |
五、访问地址
? https://huggingface.co/manycore-research/SpatialGen-1.0
? https://github.com/manycore-research/SpatialGen
技术前瞻:据群核研究院透露,下一代模型将集成NeRF动态光照重建,支持实时材质编辑,预计2026年Q1发布测试版。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...