
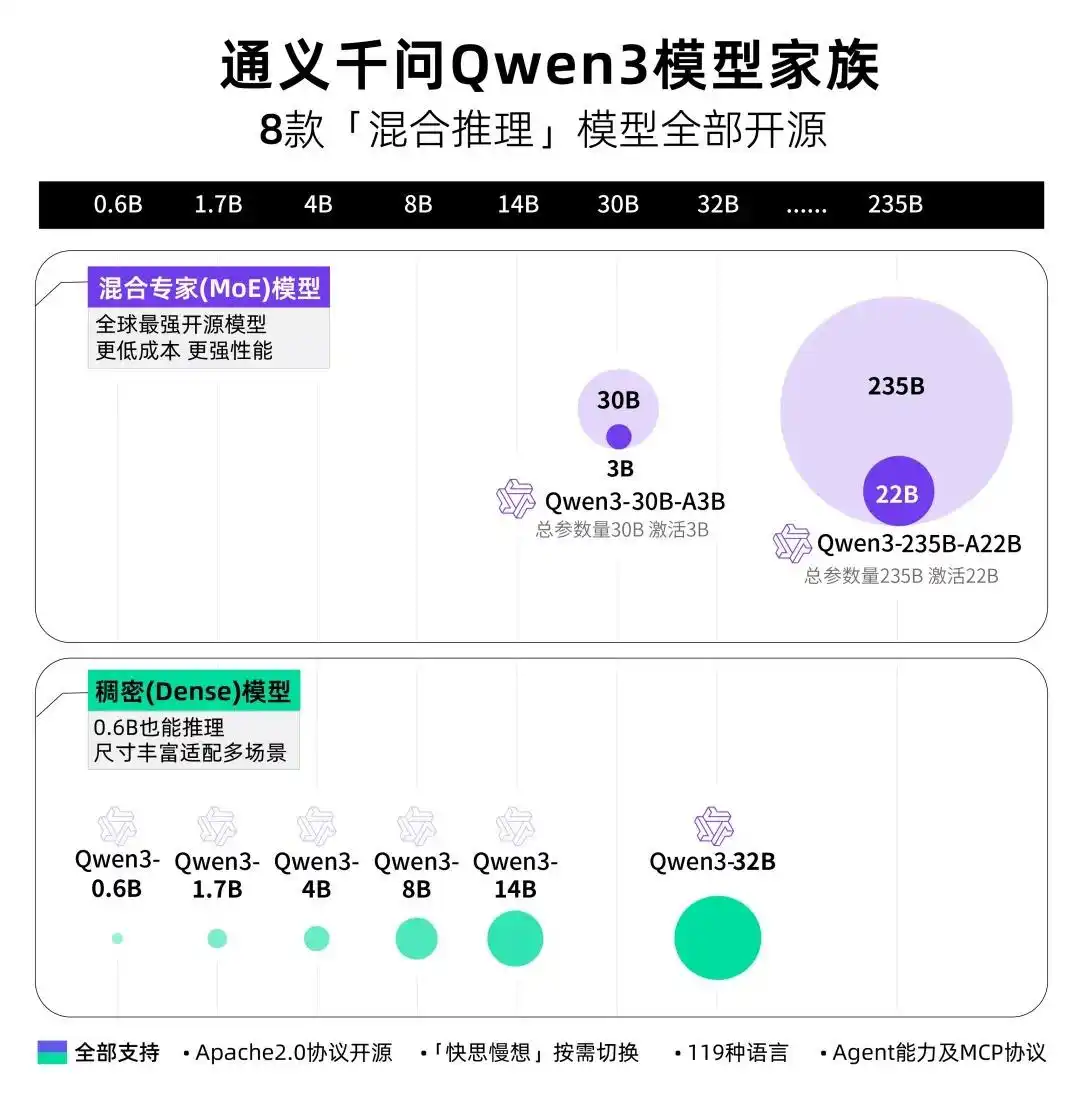
一、产品介绍:技术跃迁的里程碑之作
阿里巴巴通义千问团队于7月22日推出Qwen3-235B-A22B-Instruct-2507-FP8旗舰模型升级版。此次更新彻底告别混合思考模式,专注非思考任务优化(Non-thinking),在指令响应速度与精度上实现质的飞跃。最令人振奋的是,它在多项关键指标上同时超越开源与闭领域顶尖模型,包括:
- 数学能力:AIME25测试得分70.3(DeepSeek-V3仅46.6)
- 编程实力:LiveCodeBench v6得分51.8(Kimi-K2为48.9)
- 逻辑推理:ZebraLogic测试95.0分,碾压第二名6分差距
二、适用人群:谁更需要这款AI核武器?
| 用户类型 | 典型场景 | 核心价值点 |
|---|---|---|
| 开发者 | 代码生成/调试 | 256K上下文支持长项目分析 |
| 企业用户 | 文档分析/决策支持 | 工具调用降低开发成本 |
| 科研工作者 | 数学建模/论文研读 | STEM领域精度提升30%+ |
三、核心功能:重新定义AI生产力边界
? 超强指令遵循
技术原理:采用分层知识蒸馏技术压缩模型体积18%,结合94层GQA(分组查询注意力)架构
实际效果:用户实测反馈“严格遵循提示词能力远超同类模型”,尤其在生成复杂代码(如HTML全栈POS系统)时细节精准度提升显著? 256K超长上下文
技术原理:改进Rotary Position Embedding技术,上下文窗口扩展300%至262,144 tokens
场景价值:单次处理整本书籍/大型代码库,金融报告分析效率提升4倍? 多语言长尾知识覆盖
技术原理:36T tokens训练数据(Qwen2.5的两倍),覆盖119种语言方言
突破性进展:藏语/南岛语系等小众语言问答准确率提升55%? Agent工具智能体
技术原理:原生支持MCP协议,BFCL-v3测试达70.9分(人类专业水平97.3)
开发利器:内置Qwen-Agent框架,工具调用解析器降低编码复杂度? 人类偏好深度对齐
技术原理:四阶段RLHF优化,Arena-Hard v2得分79.2
用户体验:生成内容更自然,开放性任务回复“人性化”感知提升40%⚡ FP8高效推理
技术原理:FP8混合精度计算降低40%显存占用,4张H20 GPU即可部署
商业价值:企业级部署成本下降35%,推理延迟优化至毫秒级
四、工具使用技巧:解锁隐藏战力
代码生成黄金指令
使用Qwen-Agent调用工具模板: from qwen_agent.tools import WebExtractor tool = WebExtractor() tool.run("https://example.com", instruction="提取核心论点")搭配LiveCodeBench优化解析器可避免JSON格式错误
长文档处理秘籍
分段输入时添加[CONTINUE]标记,模型自动保持上下文连贯性多语言优化技巧
在提示词开头声明LANGUAGE: TH(泰语代码),显著提升小语种响应质量
五、访问地址:立即体验未来
开源模型下载
Hugging Face仓库
魔搭社区入口在线体验
通义千问官方聊天
? 开发者贴士:使用llama.cpp配置Flash Attention2可提升20%推理速度,30B模型需约60GB RAM资源预留
阿里此次升级不仅是一次技术迭代,更标志着开源模型首次在核心能力上系统性超越闭源产品。随着团队预告“还有大招在路上”,专注于复杂推理的Thinking版本或将开启AI竞争新纪元。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...