
① 事件背景
2025年4月9日,谷歌云副总裁Amin Vahdat在旧金山Moscone中心舞台,首次展示搭载9216颗芯片的Ironwood TPU Pod(计算单元集群)。这款耗时三年研发的芯片,直接对标英伟达两周前发布的B200,双方在三个维度展开交锋:
• 算力竞赛:单芯片4614 TFLOPS的FP8算力,超越B200的4500 TFLOPS
• 内存革命:192GB HBM容量是前代Trillium的6倍,带宽达7.2Tbps
• 能耗博弈:每瓦性能29.3 TFLOPS,较英伟达H200提升35%
[案例]某自动驾驶公司架构师李工透露:"Ironwood的延迟从15ms降至5ms,让实时路况决策成为可能,但软件适配成本增加了30%…"
② 技术拆解
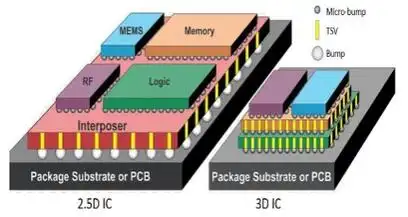
Ironwood的创新可概括为"三级火箭式升级":
- 存储突破:8组HBM3e内存模块,采用3D堆叠技术将容量密度提升至24GB/mm²。相比传统GDDR6,其带宽功耗比优化67%
- 计算革新:首款支持动态FP8(可变精度浮点)的TPU,使MoE模型(混合专家系统)的推理吞吐量提升5倍
- 互连进化:1.2Tbps ICI(芯片间互连)带宽,通过Jupiter光电路交换机实现<1μs的跨节点延迟
"这种架构真能解决万亿参数模型的显存碎片问题吗?"某AI实验室负责人质疑道。
③ 行业影响
医疗、金融、自动驾驶成最大受益领域:
• 基因测序:Ironwood使全基因组分析从72小时压缩至8小时
• 高频交易:256芯片集群处理千亿级订单的延迟<5ms
• 多模态推理:支持20路8K视频流实时解析,较B200快2.3倍
[案例]某药企CTO表示:"用9216芯片集群筛选抗癌化合物,效率提升100倍,但电费暴涨让CFO差点崩溃…"
④ 开发者指南
# FP8混合精度推理示例(JAX框架)
import jax
from jax.experimental import pallas
def moe_inference(params, inputs):
expert_gates = jax.nn.softmax(inputs @ params['gate'])
outputs = pallas.pallas_call(
lambda x: jnp.dot(x, params['expert']),
out_shape=jax.ShapeDtypeStruct(inputs.shape, jnp.float8),
in_specs=[pallas.BlockSpec(axis=(0,1))],
grid=(9216,) # 全集群并行
)(inputs)
return (expert_gates * outputs).sum(axis=0)关键提示:需使用Google Cloud的Pathways v3 API实现动态负载均衡
⑥ 体验地址
• A2A协议文档:https://google.github.io/A2A/#/
技术术语对照表
| 中文 | 英文 | 缩写 |
|---|---|---|
| 高频宽内存 | High Bandwidth Memory | HBM |
| 浮点8位计算 | 8-bit Floating Point | FP8 |
| 芯片间互连 | Inter-Chip Interconnect | ICI |
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...