① 事件背景:性能神话VS生态困局
自2024年Q3流片传闻流出,昇腾930便陷入「数据迷雾」:华为官方始终未公布完整参数,但2025年春晚搭载该芯片的工业机器人完成0.02秒级质检任务,同期某AI实验室泄露的ResNet50训练测试显示,其效率达英伟达H100的72%。
争议焦点集中于两大矛盾:
- 硬件跃进与软件滞后:昇腾910系列虽在FP16浮点运算达256TFLOPS,但开发者反馈CANN平台(昇腾异构计算架构)文档不全、调试困难,与CUDA(英伟达并行计算平台)生态差距明显
- 算力堆砌与应用失衡:1024TOPS的INT8算力虽惊艳,但实际业务场景中,多数企业仍受限于模型压缩、多芯片组网技术
[案例] 某自动驾驶公司CTO李工透露:「昇腾930单卡推理速度比H100快17%,但部署3节点集群时,片间通信延迟陡增42%,这迫使我们重写分布式训练代码。」
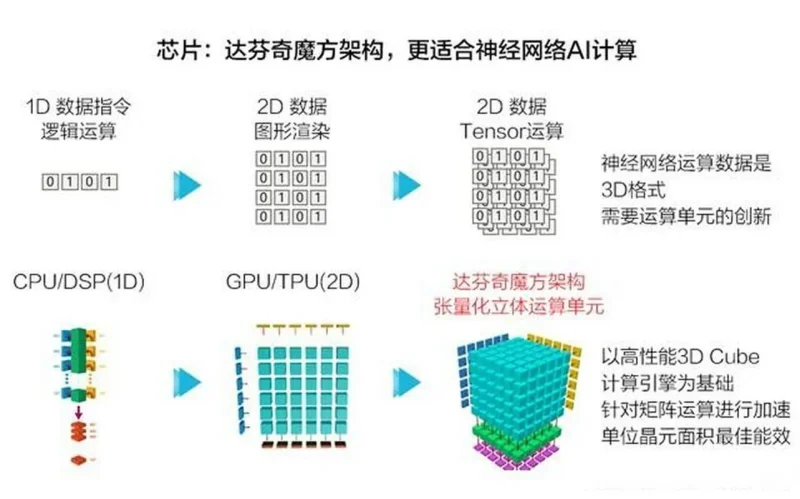
② 技术拆解:达芬奇架构3.0的攻守道
硬件层:双7nm工艺的暴力美学
昇腾930采用SMIC(中芯国际)N+2 7nm工艺,集成1024个AI Core(人工智能核心)。每个Core包含:
• 立方体计算单元(3D Cube):专攻矩阵运算,支持FP16/INT8混合精度
• 矢量处理器(Vector Engine):处理非规则数据流,如图像预处理
• 任务调度器:基于强化学习的动态功耗分配(参考MindSpore强化学习模块)
软件层:CANN 8.0的生态破冰
针对开发痛点,新版CANN平台主要升级:
# Python示例:昇腾930多卡训练加速(基于MindSpore 2.3)
import numpy as np
from mindspore import context
context.set_context(device_target="Ascend", device_id=0)
# 自动混合精度+内存优化
net = Net()
net.to_float(mstype.float16)
model = Model(net, amp_level="O3") # O3级优化减少显存占用30%
# 跨设备梯度同步
from mindspore.communication import init
init("hccl") # 华为集合通信库,替代NCCL 
技术争议点:CANN 8.0虽支持PyTorch算子自动迁移,但实测ResNet50需手动改写18%代码,这种半开放生态真能吸引开发者?
③ 行业影响:冰火两重天的落地图景
• 训练芯片:英伟达58% / 昇腾29% / 其他13%
• 推理芯片:昇腾41% / 英伟达32% / 寒武纪27%
工业领域:华为与蔚来合作的车灯质检系统,实现单设备检测速度0.8秒/件(较人工提效15倍),但部署成本达28万元/台,中小厂商望而却步。
大模型训练:DeepSeek R1在昇腾集群训练时,Token处理速度达2.4万/秒(对比A100集群提升60%),但需定制液冷机房,抬高基建投入。
④ 开发者指南:避坑指南与加速秘籍
边缘部署优化方案
// JS示例:浏览器端模型轻量化(适配昇腾310边缘芯片)
const model = await tf.loadGraphModel('ascend://mobilenet_v2');
const img = tf.browser.fromPixels(camera);
const res = model.execute(img.resizeBilinear([224,224]));
// 启用INT8量化
const quantModel = await model.quantize({
scheme: 'ascend_int8', // 昇腾专属量化方案
calibData: calibrationSamples
}); [案例] 某智慧园区开发商张工建议:「使用MindSpore的AutoTune工具(自动超参优化),推理延迟可从53ms降至37ms。」
⑤ 趋势预测:从技术秀到生态战的拐点
根据Gartner 2025技术成熟度曲线,昇腾930正处于「期望膨胀期」顶峰,未来18个月将经历生态成熟度考验:
• 短期(2025-2026):凭借政务、央企订单维持35%+增速
• 中期(2027-2028):CANN与PyTorch框架深度融合决定开发者留存率
• 长期(2029+):3D堆叠芯片+光子互联技术或成超车机会点
技术术语表
| 中文 | 英文 | 简写 |
|---|---|---|
| 达芬奇架构 | Da Vinci Architecture | DVA 3.0 |
| 异构计算架构 | Compute Architecture for NN | CANN |
| 张量处理单元 | Tensor Processing Unit | TPU |
| 统一缓冲区 | Unified Buffer | UB |
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...