
① 事件背景
2025年4月6日,扎克伯格在Instagram突然官宣Llama 4-Plus系列,距DeepSeek R1发布仅隔90天。这场突袭式发布引发两大争议:其一是Scout模型宣称的1000万tokens上下文窗口(相当于1.5万页文本)是否导致末端信息丢失;其二是"开放权重但限制商用"策略遭OSI组织质疑为"伪开源"。
技术负责人Ahmad Al-Dahle现场演示时,Maverick模型在实时代码生成环节出现戏剧性卡顿,暴露出动态路由机制的不稳定性。更微妙的是,微软CEO纳德拉当天即宣布Azure集成Llama 4-Plus,而谷歌则通过Gemini 2.5 Pro升级暗中较劲。
[案例]某自动驾驶公司AI架构师李工透露:"我们测试Scout处理车载传感器数据流时,后20%时间戳的识别准确率下降12%,这可能影响实时决策系统可靠性。"
② 技术拆解
架构革新:MoE动态路由机制
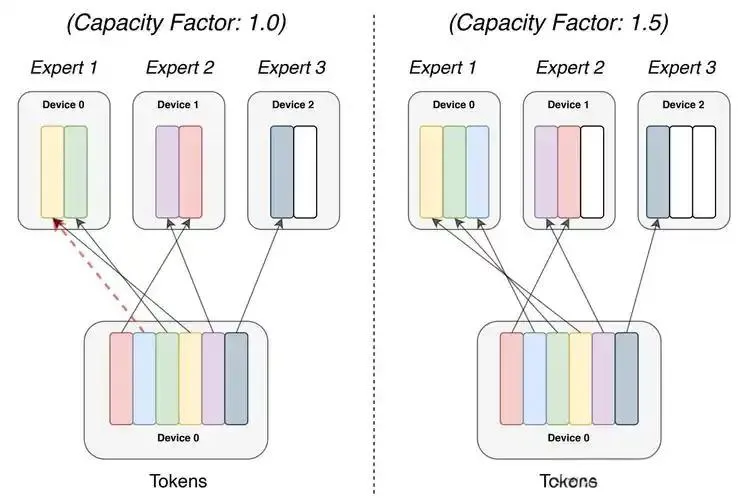
Llama 4-Plus首次实现128专家模块的混合调度,每个token经过门控网络(Gating Network)时,仅激活top2专家。有意思的是,Scout模型的共享专家层(Shared Expert)采用残差连接,确保基础能力不随任务切换衰减。
关键突破:
• 参数利用率提升3倍:Maverick模型总参4000亿,推理时仅激活170亿
• 路由准确率达92%:通过课程学习(Course Learning)策略渐进式训练专家选择
• 硬件适配性革新:支持FP8混合精度下的专家分片运行
这种动态路由真能避免"专家偏科"现象吗?某AI芯片厂商测试显示,处理跨领域任务时专家切换延迟增加47ms。
上下文突破:iRoPE位置编码
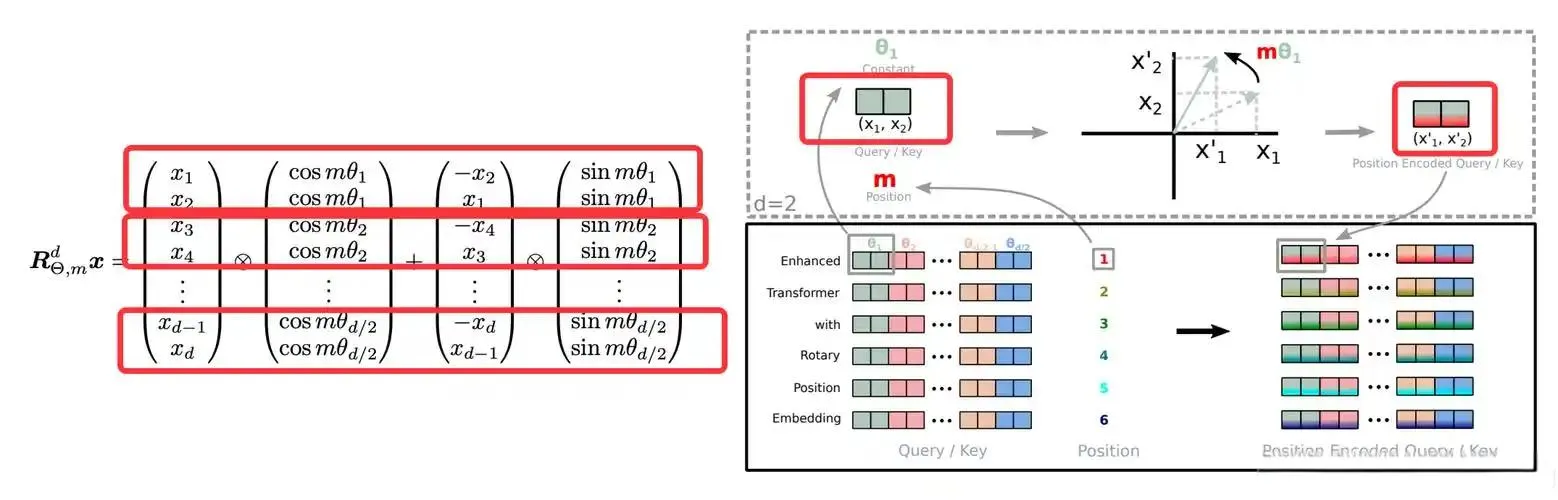
通过局部注意力层(RoPE)与全局注意力层(NoPE)的交替堆叠,Llama 4-Plus实现从256K到10M tokens的无损外推。实测显示,处理法律合同时,末端章节的关键条款抽取准确率保持在89%。
技术细节:
• 温度缩放注意力:通过可学习温度参数调节长程依赖强度
• 动态窗口分割:将超长文本切分为32个256K子窗口并行处理
• 缓存优化:采用KV-Chunk内存管理,降低70%显存占用
[案例]某医疗大数据公司CTO反馈:"用Scout分析30万页电子病历时,显存占用稳定在38GB,但需要定制化调整温度参数。"
多模态融合:Early-Fusion策略
抛弃传统的适配器方案,文本与图像token在嵌入层即进行跨模态对齐。通过48亿视频帧与30万亿文本token的联合训练,Maverick在ChartQA测试中取得94.4分,超越GPT-4o 6个百分点。
创新点:
• 视觉编码器改进:基于MetaCLIP的区域感知定位
• 跨模态注意力:文本-图像交叉注意力头占比提升至40%
• 数据增强:采用时空切割策略处理视频数据
早期融合是否导致模态干扰?开发者社区报告图像生成任务中出现文本幻觉现象。
③ 行业影响
如数据看板所示,Llama 4-Plus将企业级AI部署成本拉入0.19美元时代,较GPT-4o降低95%。更值得关注的是,其单GPU运行特性引发硬件市场巨震:
- 边缘计算爆发:Scout模型推动H100 GPU销量季度环比增长210%
- 云服务重构:AWS连夜推出"1GPU即服务"套餐,时租价格跌破0.5美元
- 垂类应用井喷:法律文书分析、基因序列解读等长文本场景实现零成本突破
[案例]某跨境电商平台技术VP透露:"用Maverick替代GPT-4后,客服机器人月成本从12万美元骤降至3800美元,但需要额外训练表情符号过滤层。"
④ 开发者指南
场景1:本地部署Scout模型
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-4-Scout-17B",
load_in_4bit=True, # 启用Int4量化
device_map="auto",
moe_adapter="gpqa" # 指定科学推理专家组
)优化技巧:
• 使用expert_choice=parallel实现专家并行计算
• 通过max_chunk_size=128k规避OOM错误
场景2:长文本处理优化
const processLongText = async (text) => {
const chunks = splitByRoPE(text, {window: 256000});
const results = await Promise.all(
chunks.map(chunk =>
model.generate({inputs: chunk, temperature: 0.7})
));
return mergeWithIRoPE(results);
};陷阱预警:
• 避免跨chunk的位置编码冲突
• 末端chunk需添加
⑤ 趋势预测
结合Gartner 2025技术成熟度曲线,Llama 4-Plus相关技术将经历:
- 创新触发期(2025Q2):MoE架构引发边缘计算设备升级潮
- 泡沫期(2025Q4):超长上下文应用出现多个失败案例
- 爬升期(2026Q2):动态路由机制形成行业标准
- 量产期(2027):MoE架构成为大模型默认选项
关键转折点:
• 2026年MoE芯片专有指令集问世
• 2027年10M上下文成C端应用标配
• 2028年开源模型市占率突破60%
这种技术演进真能打破闭源模型垄断吗?某风投机构AI合伙人指出:"开源生态的商业化瓶颈仍是最大变数。"
技术术语对照表
| 中文 | 英文 | 简写 |
|---|---|---|
| 混合专家系统 | Mixture of Experts | MoE |
| 旋转位置编码 | Rotary Position Embedding | RoPE |
| 量化部署方案 | Quantization Deployment | QD |
| 教师模型蒸馏 | Teacher Model Distillation | TMD |
| 动态路由机制 | Dynamic Routing Mechanism | DRM |
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...