
? 产品介绍
开发商:谷歌DeepMind
定位:全球首个支持音画同步生成的第三代AI视频模型
突破性升级:2025年7月向Google Flow平台订阅用户开放
| 属性 | 说明 |
|---|---|
| 输入方式 | 单张图片 + 文本提示(可选) |
| 输出质量 | 最高4K分辨率,带环境音效/人声 |
| 生成时长 | 8秒起(分段生成最长60秒) |
| 核心突破 | 多镜头角色一致性 + 音画同步生成 |
? 谁适合Veo 3?
- 影视创作者:快速生成分镜预演,降低特效成本达70%
- 广告营销人:1天制作千人千面广告,成本从50万→500美元
- 自媒体博主:单人完成口播视频+背景音效,无需后期
- 动漫设计师:实现角色跨场景一致性,加速IP开发
- 教育工作者:生成历史场景/科学实验的沉浸式视频
⚙️ 五大核心功能与技术解析
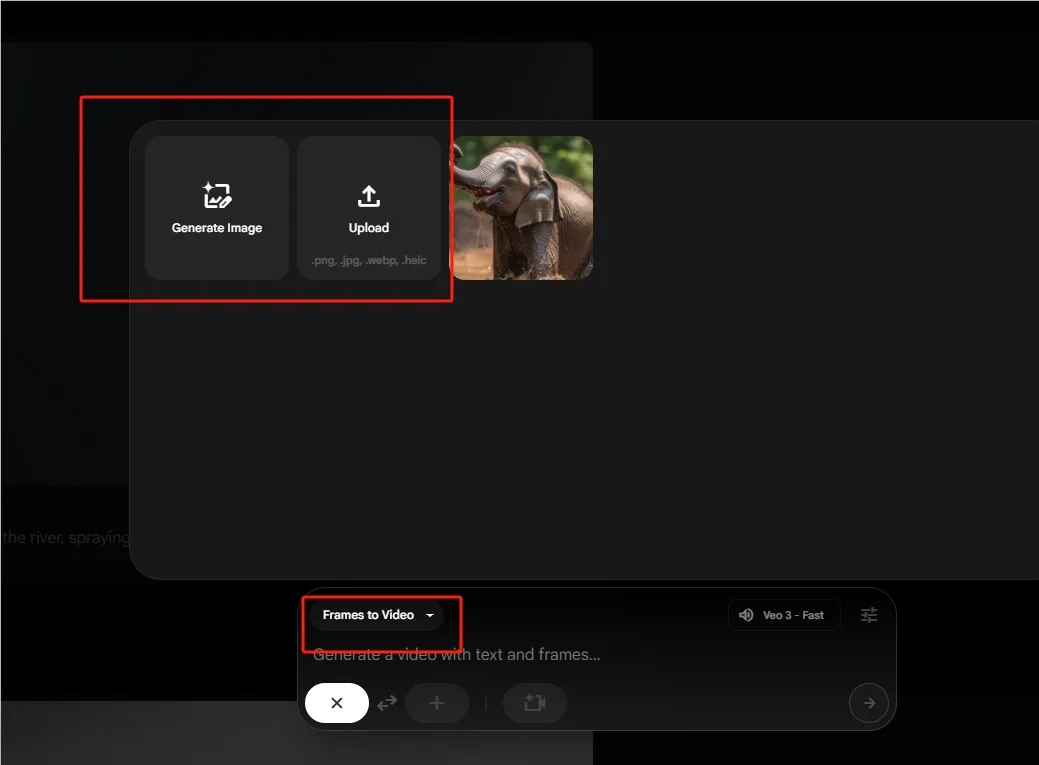
1. 单图生成音视频(Frames to Video)
操作路径:Flow平台 → 上传图片 → 选择"Frames to Video"
技术原理:
通过图像编码器提取视觉特征,结合潜空间扩散模型生成时序帧,同步触发V2A技术解析画面语义,动态匹配环境音/人声。
? 实测效果:Midjourney生成的角色图,可转化为带台词口播的香奈儿广告
2. 多镜头角色一致性
技术核心:Character Anchor锚定算法
- 自动识别人物发型、服饰等特征向量
- 通过跨帧特征绑定确保不同运镜下角色统一
❗ 注意:需在提示词首部固定角色描述(例:"20岁黑发男性,穿橄榄绿夹克…")
3. 专业级运镜控制
支持模式:
- 推镜头(Dolly in)
- 360°环绕(添加"360°"关键词)
- 首尾帧定位(不可同时选择)
? 技巧:输入"slow motion shot"可生成电影慢镜头
4. 双模式生成策略
| 模式 | 耗时 | 分辨率 | Credits消耗 | 适用场景 |
|---|---|---|---|---|
| Fast | 1分20秒 | 720P | 20 | 快速迭代测试 |
| Quality | ≈6分钟 | 4K | 100 | 商业级成片 |
5. 物理引擎增强
突破点:
- 刚体碰撞模拟(如篮球弹跳轨迹)
- 流体动态渲染(水流/火焰)
- 环境声场建模(脚步声随距离变化)
⚠️ 局限:复杂运动仍可能失真(如体操旋转)
?️ 高手都在用的实操技巧
爆款视频生成公式
角色锚定 + 场景细节 + 运镜指令 + 音频描述
例:"30岁亚洲女性穿实验室白袍(角色锚定),在充满蓝色液体的玻璃器皿前操作(场景),Dolly in推进特写(运镜),背景有试管碰撞声+兴奋地说’实验成功了!’(音频)"
成本控制秘诀
- 草稿阶段:用Fast模式生成720P小样
- 关键镜头:切换Quality模式生成4K片段
- 避免废片:首尾帧二选一(同时选择会禁用Veo 3)
影视级创作流程
graph LR
A[Midjourney生成角色图] --> B(导入Flow平台)
B --> C{添加提示词}
C --> D1[Fast模式批量生成片段]
C --> D2[Quality模式精修关键帧]
D1 & D2 --> E[时间轴拼接]
E --> F[SynthID添加水印]? 访问信息
支持平台:Google Flow创作平台(Gemini暂不支持)
订阅方式:
- 登录 https://labs.google/flow
- 开通Pro/Ultra会员
- 在创作区选择"Frames to Video"
今日尝鲜福利:新会员赠200 Credits(可生成10段Quality视频)?
Veo 3的角色一致性突破彻底解决了AI视频的"脸盲症"痛点,而音画共生技术让创作从"拼接时代"迈入"原生时代"。虽然物理模拟仍有进步空间,但已能覆盖80%的商业场景。建议创作者重点突破:
1️⃣ IP角色矩阵开发(如动漫角色跨剧情换装)
2️⃣ 个性化UGC模板(用户上传照片生成专属故事)
3️⃣ 垂直领域解决方案(医疗培训/商品展示)
当技术门槛消失时,想象力才是最后壁垒✨
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章


暂无评论...