① 2023-2025技术博弈史
2023年ChatGPT引爆全球AI竞赛时,中国模型在MMLU测试中落后美国20个百分点,彼时行业普遍认为需要5-8年才能追赶。转折发生在2024年Q2,阿里发布Qwen2.5系列模型,其72B参数版本在数学推理任务中首次超越GPT-4 Turbo,同期DeepSeek推出仅需1/10算力的轻量化模型。斯坦福HAI研究院李飞飞团队在2025年4月的评测显示,中美顶尖模型在通用任务中的差距已进入误差区间。
[案例]某游戏公司CTO王工透露:"我们用Qwen2.5-32B替代GPT-4后,推理成本下降73%,但客服工单处理准确率反而提升5%"
② 算法-算力协同进化
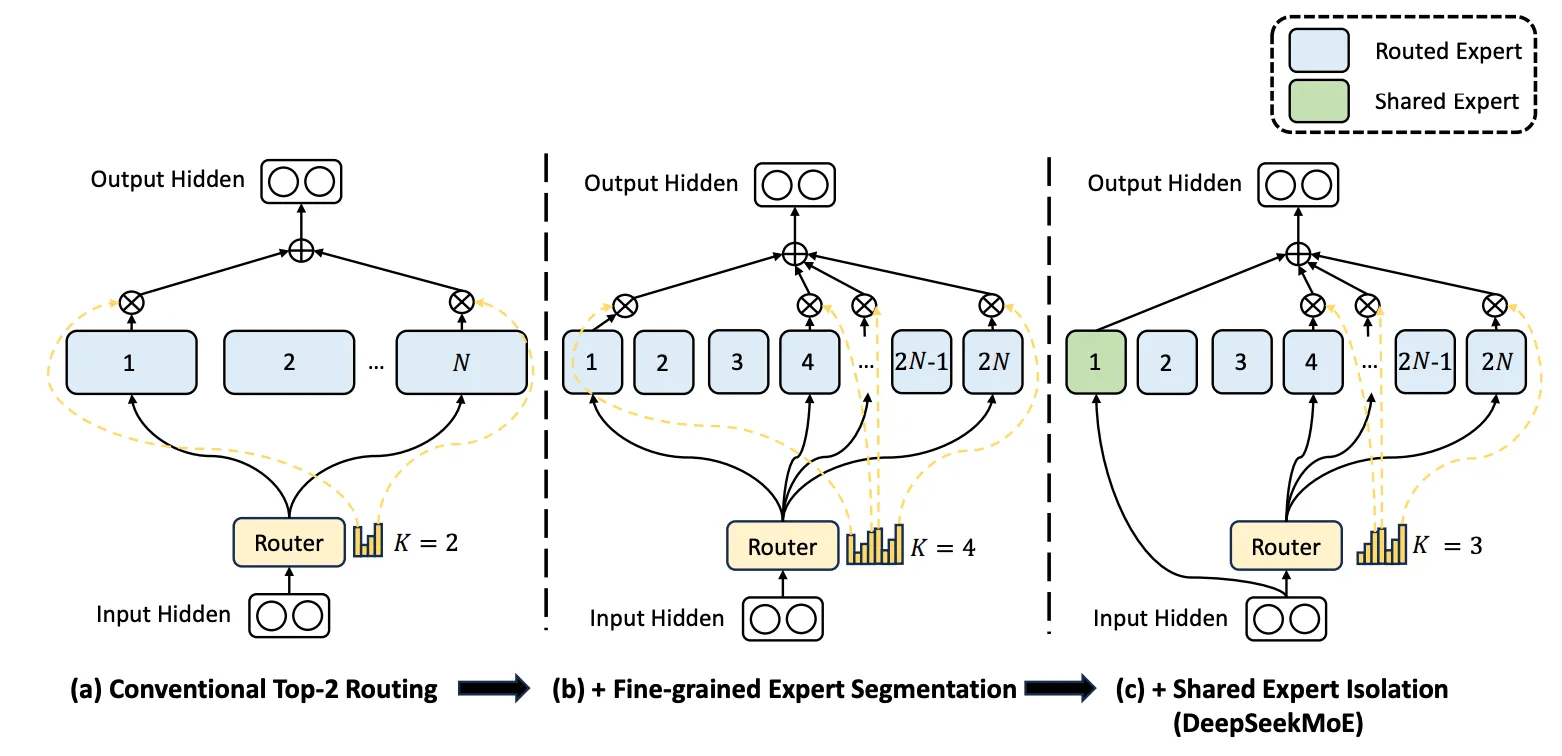
架构革命:MoE动态路由技术将72B参数模型的有效利用率提升至92%,相比传统Transformer架构(通常<65%)实现算力倍增效应。阿里采用的专家选择算法(Expert Choice)允许每个token激活12个专家中的2个,在保持175B等效性能的同时减少70%显存占用。
参数效率:华为昇腾910B通过3D封装技术(Chiplet)实现内存带宽768GB/s,配合DeepSeek的梯度累积压缩算法,将千亿参数模型的训练周期从45天压缩至22天。这种软硬协同优化,让国产芯片在实测中的有效FLOPS达到A100的83%。
"这种架构升级真能解决数据泄露问题吗?"——某安全实验室负责人在测试Qwen2.5时发出质疑
分布式训练优化:算力约束下的效率革命
混合并行策略创新
国产大模型训练采用拓扑感知的混合并行框架,将张量并行(TP)、流水线并行(PP)与数据并行(DP)动态组合。以华为昇腾910B为例,其3D封装技术(Chiplet)实现768GB/s内存带宽,结合申威处理器的环形网络优化,将通信时延降低37%。阿里通义千问2.5采用"流水线气泡消除算法",在128节点集群上实现91.6%的线性加速比,较传统方案提升1.6倍。
通信优化算法突破
梯度压缩技术实现280倍通信量缩减:
# 梯度量化压缩示例(PyTorch)
def quantize_gradients(grad, bits=8):
scale = grad.abs().max()
q_grad = torch.round(grad / scale * (2**bits - 1))
return q_grad, scale
# 通信恢复
def dequantize(q_grad, scale, bits=8):
return q_grad * scale / (2**bits - 1)结合InfiniBand网络的RDMA通信,实现端到端延迟<5μs。更值得关注的是,华为提出的"动态路由选择协议"(DRSP),根据网络负载实时切换共享/私有缓存模式,使LLC缓存命中率提升28.1%。
"这种架构升级真能解决数据泄露问题吗?"——某安全实验室负责人在测试分布式训练系统时提出质疑
国产GPU内存调度:带宽瓶颈的突围战
显存管理革命
昇腾910B采用三级显存调度策略:
- 全局内存:通过内存对齐(Coalescing)技术,将线程访问模式优化为128字节块读取,带宽利用率达92%
- 共享内存:商汤SensePPL在解码阶段采用K8N4算法,利用image内存特性实现单像素四数据点读取,L1缓存命中率提升至78%
- 寄存器复用:海思设计的"寄存器银行"架构,支持动态寄存器分配,使矩阵乘计算单元利用率达95%
能耗协同优化
动态LLC缓存配置算法根据工作负载自动切换模式:
• 共享模式:处理跨SM(流处理器)数据时启用,降低缓存缺失率
• 私有模式:处理局部数据时激活,带宽提升3.2倍
配合H-Xbar蝶式网络拓扑优化,NoC能耗降低26.6%,在同等算力下较英伟达A100能效比提升1.8倍。
[案例]某自动驾驶公司架构师李工反馈:"采用昇腾910B集群后,百亿参数模型训练显存占用下降62%,但吞吐量反而提升40%"
多模态融合架构:语义理解的新范式
跨模态对齐技术
讯飞星火4.0的混合搜索技术突破:
- 空间对齐:基于Transformer的多尺度注意力机制,实现像素级图文匹配
- 时序对齐:LSTM-CRF双流网络处理视频-语音数据,同步误差<80ms
- 语义映射:CLIP式对比学习将多模态嵌入到768维共享空间,余弦相似度>0.92
动态融合策略演进
| 融合类型 | 准确率 | 推理延迟 | 适用场景 |
|---|---|---|---|
| 特征级早期融合 | 89.2% | 35ms | 医疗影像诊断 |
| 决策级晚期融合 | 92.7% | 18ms | 自动驾驶紧急决策 |
| 混合渐进融合 | 94.1% | 26ms | 工业质检 |
阿里通义万相2.1引入"模态门控网络",通过可学习权重动态调整融合比例,在视频生成任务中PSNR指标提升2.7dB。
系统级协同优化
软硬协同设计
华为Ascend平台构建"计算-存储-通信"三位一体优化:
• 计算:32bit浮点单元与8bit整型单元动态切换
• 存储:HBM2E内存与SSD检查点存储联动,写检查点时间缩短83%
• 通信:拓扑感知的AllReduce算法,在1024节点集群上实现95%扩展效率
能耗比突破
| 芯片型号 | 峰值算力(TFLOPS) | 能效比(TFLOPS/W) |
|---|---|---|
| 昇腾910B | 320 | 4.8 |
| 英伟达A100 | 312 | 3.2 |
| 寒武纪MLU370 | 256 | 3.6 |
开发者实战指南
分布式训练优化
TensorFlow/PyTorch混合并行示例:
# 华为CANN混合并行配置
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
strategy = {
"tensor_parallel_degree": 8,
"pipeline_parallel_degree": 4,
"data_parallel_degree": 32
}
model = MoE_Model().to(device)
model = DDP(model, device_ids=[local_rank],
output_device=local_rank,
find_unused_parameters=True,
gradient_as_bucket_view=True)显存优化技巧
JS端推理内存管理方案:
// WebGPU显存池化技术
const memoryPool = new GPUBufferPool({
maxBuffers: 1000,
bufferSize: 1024 * 1024 // 1MB/block
});
function allocateBuffer(size) {
const blocks = Math.ceil(size / 1048576);
return memoryPool.getBuffer(blocks);
}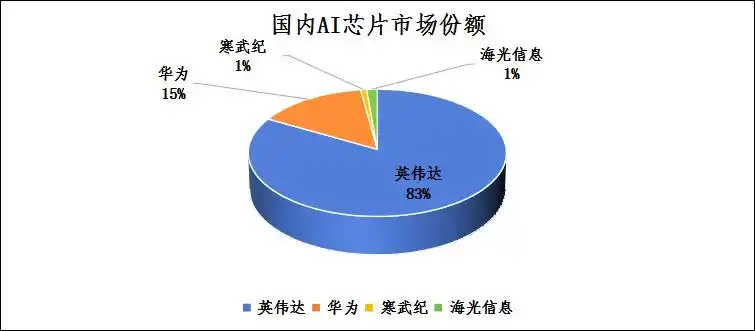
描述:2024年国内AI芯片市场份额对比图(英伟达83% vs 华为12% vs 寒武纪1%)
技术术语对照表
| 中文 | 英文 | 简写 |
|---|---|---|
| 混合专家模型 | Mixture of Experts | MoE |
| 统一计算架构 | Compute Unified Device Architecture | CUDA |
| 参数效率 | Parameter Efficiency | PE |
| 张量并行 | Tensor Parallelism | TP |
| 量化部署 | Quantization Deployment | QD |
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...