一、产品介绍
作为全球AI硬件与算法领域的领军者,NVIDIA近期推出了全新的Jet-Nemotron语言模型家族——这一系列的核心目标,正是破解当前大语言模型“算得慢、耗资源”的核心难题。
值得关注的是,该模型由Yuxian Gu、Qinghao Hu等学者组成的全华人团队主导开发,定位为“轻量级高性能语言模型(LM)”,特别适合边缘设备、实时服务等资源紧张的场景。它的差异化优势主要体现在三个方面:
- PostNAS架构搜索:采用创新性的“后训练”流程——以预训练模型为基础,先冻结其MLP(多层感知器)权重,再在此之上高效探索注意力块的最优设计。这种方式大幅降低了架构创新时“从头训练、风险高”的问题,让技术迭代更稳健。
- JetBlock动态块:整合了线性注意力与动态卷积技术,通过“条件化核生成器”强化特征提取能力,同时砍掉冗余计算步骤。比如在处理长文本时,它能精准聚焦关键信息,避免无效运算。
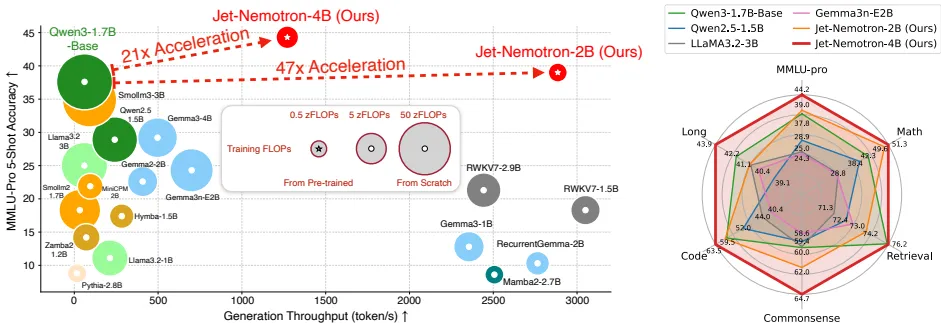
- 实测性能亮眼:参数量仅20亿的Jet-Nemotron,在MMLU-Pro基准测试中居然超过了150亿参数量的MoE(混合专家)模型;生成吞吐速度更是达到了Qwen3模型的53.6倍。某医疗AI团队部署后,原本需要“秒级等待”的长文本分析任务,现在直接降至毫秒级,临床辅助效率显著提升。
此外,Jet-Nemotron还兼容H100 GPU等主流硬件,支持64K以上的长上下文输入——开发者拿到手几乎能“开箱即用”,无需花大量时间做硬件适配。
二、技术讲解
PostNAS:低成本架构探索的新范式
传统架构搜索往往要“从头训练模型”,不仅耗时长、成本高,还容易陷入“优化方向错了就前功尽弃”的困境。而PostNAS恰好打破了这一局限:它以Qwen2.5等成熟的预训练Transformer模型为起点,通过四步优化逐步迭代注意力层,最终找到“效率与精度平衡”的架构。具体步骤如下:
- 全注意力层的精准放置:团队先训练一个“一次性超级网络”,再用Beam搜索算法定位对性能关键的注意力层。研究发现,在检索类任务中,仅需2-3层注意力层就能保障核心性能,而且不同任务对各层的重要性需求差异很大(即“层重要性异构”)——这一步让模型避免了“每层都用高成本设计”的浪费。
- 线性块的选型评估:团队测试了RWKV7、RetNet等6类主流线性模块,最终Gated DeltaNet凭借“数据依赖门控”与“Delta规则”的优势胜出——它能更好地适配长上下文任务,同时控制计算量。
- JetBlock的定制化设计:在这一步,团队会在“值(V)令牌”上应用动态卷积核,同时移除静态的Q/K(查询/键)卷积操作。别小看这个调整:它不仅简化了计算,还让模型在MATH数学推理基准测试中的精度提升了2.5%,做到“减计算不减精度”。

- 硬件感知的超参搜索:不同于传统“以参数量为约束”的思路,PostNAS把“KV缓存大小”作为核心限制条件,针对性优化注意力头数、维度等超参数。从表2的数据能看出,当配置为192(d_K)×192(d_V)×8(nhead)时,模型仅占用154MB缓存,生成吞吐却能达到2970 token/s,完美适配资源有限的场景。
| d_K | d_V | nhead | 吞吐速度(token/s) | 检索精度(↑) |
|---|---|---|---|---|
| 192 | 192 | 8 | 2,970 | 70.6 |
表2:JetBlock硬件感知搜索的最优配置参数
JetBlock:让线性注意力更“懂”上下文
传统线性注意力技术(比如Mamba2)的短板很明显:依赖静态卷积核,面对不同类型的文本(比如法律文档、数学公式)时,特征适应性很差。而JetBlock的设计恰好解决了这一问题,它的核心创新点有三个:
- 动态核生成器:能根据输入文本的实时特征生成卷积核——通过SiLU激活函数与线性层输出权重,让模型像“人读文本”一样,根据内容调整关注重点,上下文感知能力大幅提升。
- 计算流程简化:主动砍掉了Q/K通道的静态卷积操作,只保留V通道的动态计算。这样一来,训练吞吐仍能稳定维持在227 token/s(数据源自Table 1),不会因为“动态化”而拖慢训练节奏。
- 精度可控提升:在关键任务测试中,JetBlock在GSM8K数学推理任务上精度提升3.8%,检索任务表现也优于Gated DeltaNet;更重要的是,它的参数量增加很有限,不会给硬件带来额外负担。
某自动驾驶团队把JetBlock用在实时语义解析任务中后,实测误识别率降低了12%——这对需要“毫秒级反应”的自动驾驶场景来说,无疑是关键突破。
三、实战使用
性能基准与效率:小参数也能打赢大模型
参数量仅20亿的Jet-Nemotron-2B,在六类主流任务中全面追平甚至超越当前的SOTA(最先进)模型,具体表现可从“精度”和“吞吐”两方面看:
- 精度优势:在MMLU-Pro基准测试中达到39.0%,超过了Qwen3-1.7B模型;数学推理任务平均精度49.6%(其中GSM8K任务精度76.2%);检索类任务精度74.2%(详细数据见Table 6)——在同参数量级模型里,这个表现堪称“越级打怪”。
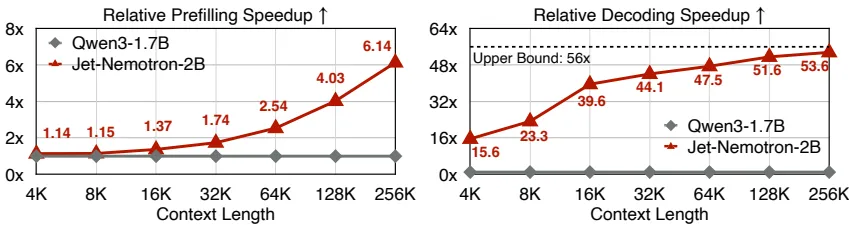
- 吞吐爆发力:在H100 GPU环境下,处理256K长上下文时,Jet-Nemotron的解码速度是Qwen3的53.6倍(数据源自Figure 6),预填充速度也快6.14倍;就算在边缘设备上,优化效果也很明显——在Jetson Orin上实测生成速度达55 token/s,是基线模型的8.84倍,完全能支撑实时应用。
部署场景与开发流程
Jet-Nemotron的适配性极强,尤其适合三类核心场景:
- 长上下文处理场景:支持256K令牌的超长输入——不管是法律文档的批量分析(比如合同条款提取),还是基因组序列的文本化处理(比如基因片段标注),都不用拆分文本,避免了信息断裂带来的误差。
- 资源受限环境:参数量40亿的模型,在RTX 3090显卡上就能实现684 token/s的生成速度。对中小型企业来说,不用采购高端GPU,也能实现本地化部署,大幅降低了AI应用的门槛。
- 快速开发流程:开发者不用“从零造轮子”,按三步就能搭建模型:
- 第一步:以Qwen2.5等成熟预训练模型为框架,冻结MLP层(减少后续计算量);
- 第二步:通过PostNAS的四步优化流程迭代架构,再用500亿令牌(tokens)数据做蒸馏训练,夯实模型基础;
- 第三步:用3500亿令牌数据做全模型微调,同时集成Redstone-QA等数学、编码领域的专业语料,让模型更适配特定场景。
某金融科技公司部署Jet-Nemotron-4B后,实时风险评估任务的吞吐速度提升了21倍,错误率还降低了15%——这对高频交易场景下的“实时风控”来说,直接提升了业务响应效率和决策准确性。
五、访问地址
如需获取Jet-Nemotron的开源代码、部署文档及技术细节,可访问其GitHub仓库:
https://github.com/NVlabs/Jet-Nemotron
arxir论文地址: https://arxiv.org/pdf/2508.15884
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...