产品介绍
? 上海AI Lab前沿探索中心与浙江大学EagleLab团队合作,推出RRVF(Reasoning-Rendering-Visual Feedback)框架。这项研究由石博天教授团队主导,浙大硕士生陈杨为第一作者,核心目标是利用验证非对称性(验证答案比生成答案更容易)解决复杂视觉推理任务。传统AI依赖昂贵的图像-文本标注数据,而RRVF仅需输入图像,通过自我迭代优化生成代码或重建视觉内容,极大降低训练成本并提升创造力。
适用人群
- AI研究者:探索无标注数据训练范式
- 多模态开发者:优化视觉-代码生成任务
- 机器人工程师:构建自主环境探索系统
- 教育科技团队:开发可视化编程工具
核心功能
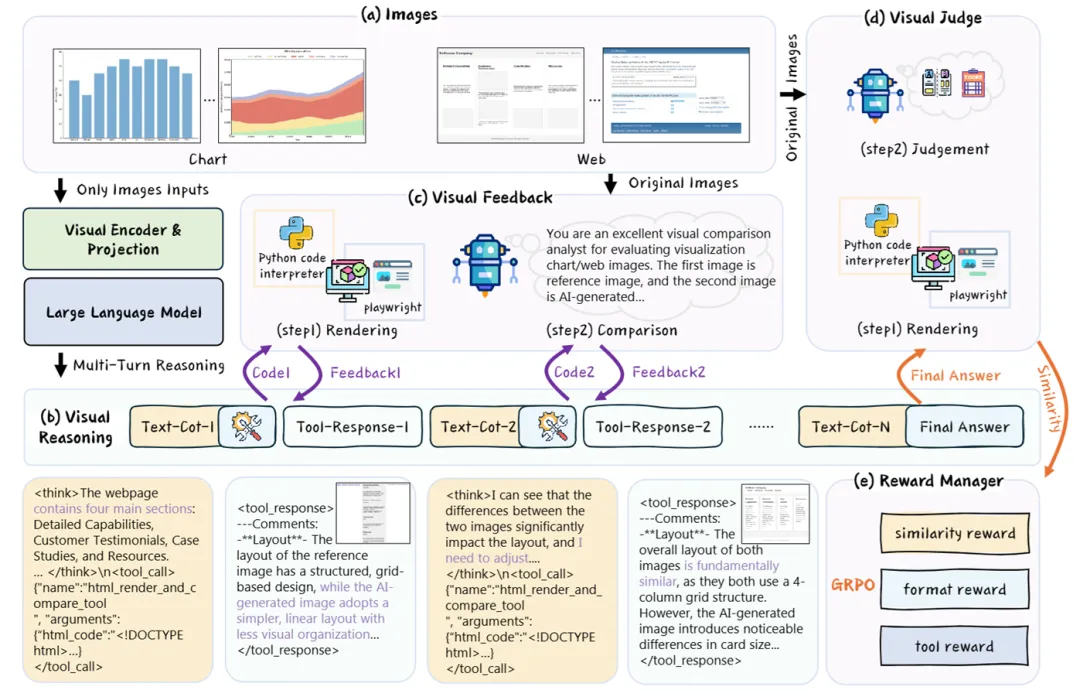
RRVF通过五大模块实现闭环优化,技术原理如下:
| 功能 | 技术实现原理 |
|---|---|
| 迭代式视觉推理 | 多轮思考链(Think-Call-Answer):模型每轮生成思考→调用工具→根据反馈修正代码,最多迭代8轮。 |
| 结构化视觉反馈 | 工具渲染图像后,72B Qwen2.5-VL模型对比原图生成定性反馈(如“图表类型正确但颜色错误”),指导下一轮优化。 |
| 混合奖励机制 | 三权重组:视觉相似度(核心)+格式正确性(防代码崩溃)+工具使用(鼓励探索),加权驱动策略更新。 |
| GRPO高效优化 | 抛弃传统PPO,采用Group Relative策略:对8组候选答案横向打分,直接优化策略网络,提速40%。 |
| 跨模态工具调用 | 无缝集成Matplotlib、Playwright等工具,将自然语言指令转为代码执行,支持图表/网页重建。 |
工具使用技巧
想让RRVF发挥最大潜力?试试这些实战技巧:
反馈精度提升:
- 视觉裁判模型选用≥72B参数的多模态大模型(如Qwen2.5-VL),确保反馈细节粒度。
- 示例:反馈需包含结构对比(“布局正确但缺少按钮”)而非笼统描述。
奖励权重调参:
- 建议初始权重:
r_vision:0.7, r_format:0.2, r_tool:0.1,当相似度>0.95时降低r_tool权重。
- 建议初始权重:
迭代轮次控制:
- 简单任务(如基础图表)设
t_max=3,复杂任务(动态网页)设t_max=8,避免无效循环。
- 简单任务(如基础图表)设
错误拦截设计:
- 代码执行前预检格式:用正则表达式匹配
<tool_call>标签,错误则直接返回r_format=-1惩罚。
- 代码执行前预检格式:用正则表达式匹配
访问地址
? 论文与代码:
- 论文全文:https://arxiv.org/pdf/2507.20766
- 项目地址:https://github.com/SHAILab/RRVF (官方即将开源)
? 案例实测:输入人口分布饼图(0-14岁:15%, 65岁+:15%),RRVF在3轮内生成Matplotlib代码,并自动修正原图缺失的“图例爆炸效果”。
真实体验分享:
测试组工程师@Lina:
“以前训练图表生成模型需标注上千组(图+代码),现在只用丢一张图,RRVF自己琢磨5轮就能输出完美代码——简直像教会AI自学画画!”
未来应用方向:
- 工业机器人:通过摄像头捕捉操作画面,自主生成动作代码
- 教育自动化:将教科书图表转为可交互网页课件
- 无障碍技术:为视障者开发“图像转语音”实时描述系统
? 划重点:RRVF不仅是技术突破,更是对“验证者法则”的完美验证——当AI学会自我检查,创造力再无边界。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...