
? 产品介绍
英伟达(NVIDIA) 在2025年7月19日正式推出OpenReasoning-Nemotron——一个专为数学、科学与代码推理而生的开源模型家族!它基于国产架构 Qwen2.5 微调,并创新性地从中国团队 DeepSeek-R1 0528(671B参数) 大模型中蒸馏知识,压缩成仅1.5B~32B的高效推理引擎,堪称“小身材、大智慧”的典范。
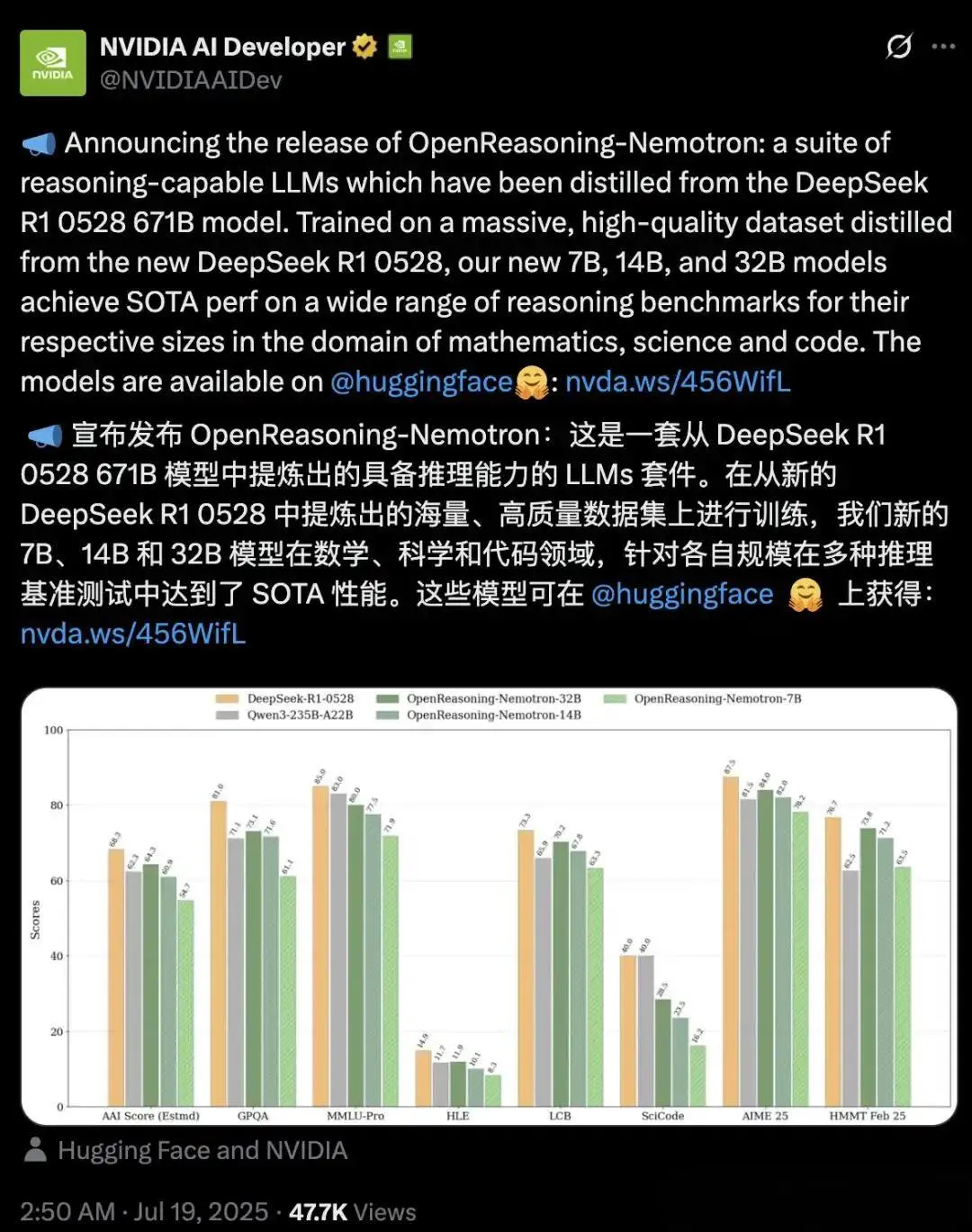
更惊艳的是,32B版本在AIME24数学竞赛拿下89.2分,开启GenSelect模式后HMMT得分飙升至96.7,直接超越OpenAI o3高算力版!而且全程仅用监督微调(SFT),完全没靠强化学习(RLHF)。
? 适用人群
| 人群类型 | 典型场景 | 推荐模型版本 |
|---|---|---|
| 学生/教育者 | 解数学题、竞赛训练、学习辅助 | 7B(性价比高) |
| AI研究员 | 模型蒸馏研究、推理优化实验 | 14B/32B(前沿性能) |
| 程序员 | 代码生成、逻辑Debug、算法验证 | 7B+GenSelect模式 |
| 工业开发者 | 工程计算、金融建模、科学仿真 | 32B(高精度) |
| 个人极客 | 本地部署、PC端推理、低成本实验 | 1.5B/7B(轻量化) |
? 核心功能(附技术原理!)
| 功能 | 技术实现原理 | 实测效果 |
|---|---|---|
| ⚡ 高阶数学推理 | 从DeepSeek-R1蒸馏500万条数学/科学轨迹,用多步链式推理(Chain-of-Thought) 强化逻辑推导 | AIME24得分89.2,超越o3-high模型 |
| ? 代码跨域泛化 | 仅训练数学数据,却通过隐式表征共享激活代码能力;LCB pass@1分数从70.2→75.3 | 数学→代码零样本迁移,无额外训练! |
| ?️ GenSelect增强模式 | 基于AIMO-2的多解生成-筛选算法,每个问题生成64个解,选最优输出 | HMMT竞赛分从73.8→96.7,质变级提升! |
| ? 长上下文推理 | 扩展至32K token上下文,支持长链推导;7B+模型显著受益 | 14B在MMLU-PRO复杂问答中刷新SOTA |
| ?️ 本地低耗部署 | 支持INT8/FP16量化,TensorRT-LLM加速;骁龙X Elite+32GB内存可跑14B模型 | 游戏PC也能流畅推理,告别云端费用! |
? 技术冷知识:
1.5B小模型为何成绩反降?——因新数据上下文扩至32K,小模型hold不住长推理链,导致精度波动;而7B以上模型则全面爆发。
?️ 工具使用技巧(亲测有效!)
✅ 技巧1:开启GenSelect榨干模型潜力
在Hugging Face调用时添加参数:
generate_kwargs = {
"do_sample": True,
"num_beams": 16, # 生成16个候选解
"num_return_sequences": 1, # 返回最佳解
"max_new_tokens": 1024
}? 注意:32B模型建议用
num_beams=64,HMMT分数可暴涨23分!
✅ 技巧2:量化运行,低配设备也能飞
用LM Studio加载模型时:
- 选INT4量化格式(如
openreasoning-7B-4bit.gguf) - 限制线程数 → 避免卡死(M系列Mac建议设6线程)
- ARM设备优先跑7B版本,x86设备可挑战14B
✅ 技巧3:Prompt里藏玄机!
- 科学问题:结尾加
Let's think step by step and verify with tools if needed. - 编程任务:添加
We are expert Python coders. We use precise syntax.这样能激活模型的“工具集成推理(TIR)”模式!
? 访问地址
模型下载(Hugging Face):
? https://huggingface.co/nvidia/OpenReasoning-Nemotron-32B- 含1.5B/7B/14B/32B全系列
在线体验(免部署):
? https://huggingface.co/spaces/Tonic/Nvidia-OpenReasoning本地运行神器(LM Studio):
⬇️ 下载地址:https://lmstudio.ai
→ 搜索框输入openreasoning→ 选版本一键加载!
最后悄悄说?:
虽然它带着“中国血统”(Qwen2.5架构 + DeepSeek-R蒸馏),但推理能力已跻身全球顶尖!更关键的是——完全开源免费。还在等?你的下一台“数学外挂”,何必是云端天价API!?
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...