? 一、产品介绍:让静态图“活”起来的黑科技
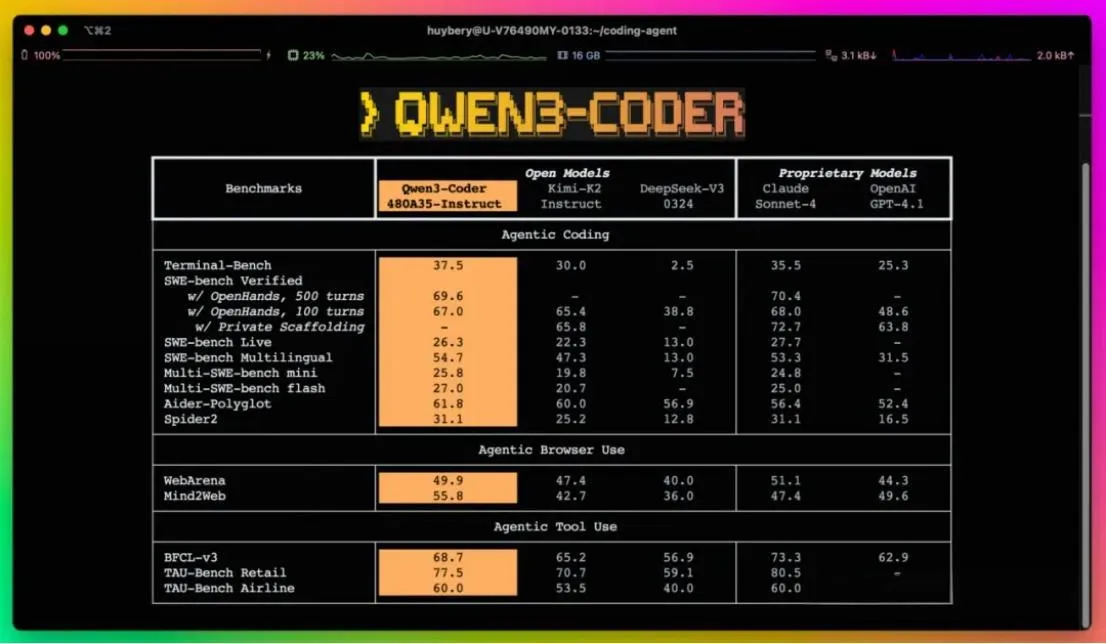
Pika Labs(由斯坦福华人团队创立)近期推出的音频驱动表演模型(Audio-Driven Performance Model),解决了传统视频制作中音画同步的行业痛点。用户只需上传一张静态图片(如自拍、插画或名人照片)和一段音频(语音、音乐或说唱),系统即可在平均6秒内生成长达不限的720p高清视频。视频中的人物不仅能实现毫米级唇形匹配,还会自然展现表情变化和肢体动作,仿佛被“注入灵魂” 。
? 二、适用人群:谁需要这个工具?
- 内容创作者:快速生成短视频/口播视频,降低拍摄成本
- 教育工作者:将历史人物图片转化为生动讲解视频
- 独立游戏开发者:为NPC角色生成动态对话
- 营销人员:制作个性化产品推广视频
- 社交媒体用户:创作趣味Meme和AI分身内容
⚙️ 三、核心功能与技术解析
| 功能模块 | 技术实现原理 | 创新价值 |
|---|---|---|
| 6秒生成能力 | 基于GAN生成对抗网络优化,生成器与判别器协同优化视频帧连贯性 | 效率提升100倍,传统特效需数小时 |
| 多模态同步技术 | 音频频谱分析+面部关键点检测,通过时序对齐算法驱动唇部肌肉模型 | 支持说唱/多语种,误差低于0.1秒 |
| 动态表情生成 | 情感识别模型(RNN)解析音频情绪,驱动52组面部微动作单元 | 眉毛挑动、嘴角变化等微表情拟真 |
| 720P高清输出 | 分层渲染技术分离背景/前景,分辨率增强模块修复边缘模糊 | 支持长视频无失真输出 |
| 全音频支持 | 非语音音频(音乐/音效)转化为身体律动,LSTM网络预测肢体轨迹 | 让蒙娜丽莎随《忐忑》摇头晃脑 |
? 四、技术原理全景图
Pika的突破源于三大技术融合:
生成对抗网络(GAN)
- 生成器:将静态图+音频编码为潜在空间向量
- 判别器:对比真实人视频与生成视频的时序连贯性
- 对抗训练使微表情更拟真
多模态对齐框架
graph LR A[音频输入] --> B(梅尔频谱特征提取) C[静态图像] --> D(3D人脸网格重建) B --> E{时序对齐引擎} D --> E E --> F[驱动参数] F --> G[视频渲染输出]ElevenLabs TTS集成
合作方提供高保真语音合成,确保音源质量(需注意:非语音类音频使用Pika自研模型)
✨ 五、工具使用技巧:避开这些坑!
图像选择黄金法则
- ✅ 优先使用正面清晰人脸(侧脸识别易崩坏)
- ❌ 避免复杂遮挡物(眼镜/口罩导致口型错位)
- ? 技巧:对非人像图片(如动物),系统会自动聚焦嘴部区域
音频处理秘籍
- 背景音乐音量≤人声,确保语音频谱清晰
- 说唱音频在句末添加0.5秒静音,提升停顿自然度
进阶创作方案
案例:生成“特朗普吐槽露营体验”视频
步骤1:用ElevenLabs生成印式英语配音
步骤2:上传特朗普正面照+露营背景图
步骤3:添加篝火音效(Pika自动生成噼啪声)瑕疵修复方案
- 手部畸变:用“手部锁定”提示词(测试版)
- 唇部抖动:开启“Stable Lip”模式(需Pro权限)
? 六、访问地址与限制说明
- 当前开放:仅限 iOS端https://pika.art/
- 权限要求:需填写邀请码(可关注官方Twitter @pika_labs 获取)
- 生成限制:免费用户每日3次生成,Pro版支持10分钟长视频
? 未来更新剧透:Web端和安卓版本预计2025Q4上线,届时将开放API接口!
? 结语:创意与边界的博弈
Pika的突破让我们看到:技术本质是创意的放大器。从让梵高讲述作画心得,到普通用户生成个人数字分身,技术正在消解专业制作的壁垒。但值得警惕的是——当任何图像都能被赋予任意声音时,真实性验证将成为社会新课题。目前建议在创作时添加数字水印(如工具自动添加的Pika Logo),为这个狂野的视频新时代保留一丝秩序。
数据来源:Pika Labs技术公告、用户实测视频、GAN原理论文(2025)、多模态学习框架研究
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...