
一、产品介绍:谷歌的影视魔法师 ?
Veo 3 是Google DeepMind在2025年I/O大会发布的第三代视频生成模型,作为谷歌旗舰AI视频工具,它首次原生集成音效生成能力——从鸟鸣声到街头噪音,甚至角色对白都能自动匹配画面。7月10日,这项技术正式登陆Gemini应用,用户可通过"图像转视频"功能将静态照片转化为动态故事短片。
更重要的是,Veo 3采用多模态Transformer架构,整合了Gemini的视觉理解技术,实现:
- 物理引擎级模拟:精准还原水流、布料运动等物理效果
- 唇形同步技术:生成角色对话时口型完美匹配发音
- 高保真压缩算法:用较小数据量保留视频关键细节
二、谁该立即尝试? ?
| 用户类型 | 应用场景 | 技术价值 |
|---|---|---|
| 内容创作者 | 快速生成短视频素材/广告片 | 节省拍摄成本80%+ |
| 教育工作者 | 将历史图片转化为动态教学材料 | 增强课堂沉浸感 |
| 营销人员 | 产品海报转互动广告 | 点击率提升验证 |
| 个人用户 | 创意生日贺卡/社交动态 | 3分钟完成专业创作 |
三、核心功能:重新定义视频创作 ✨
1. 图像驱动动态生成
- 技术原理:基于首帧控制技术(First Frame Control),通过扩散模型逐帧预测后续画面
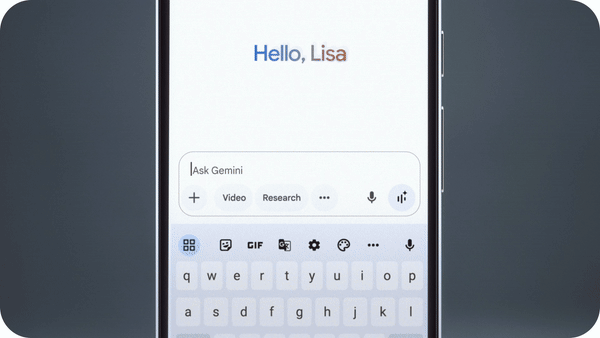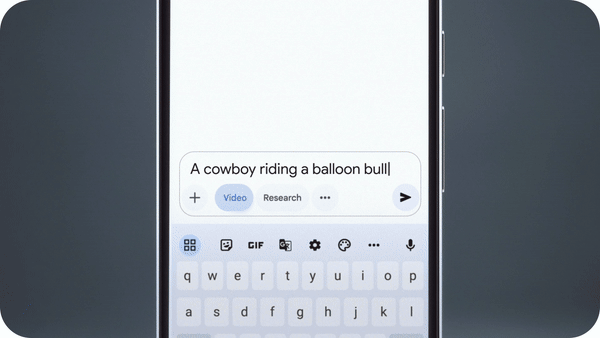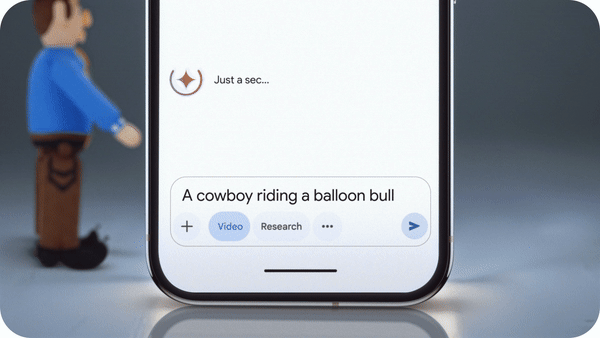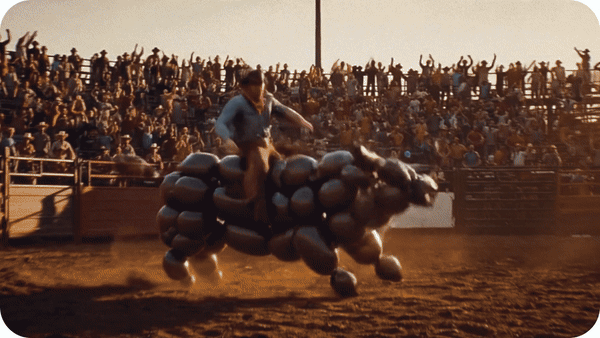
- 实操效果:上传钢铁侠图片生成战斗场景,装甲反光与动作连贯性堪比实拍
2. 多模态音效合成
- 环境音:自动识别场景添加雨声、交通噪音等背景音
- 角色对白:支持语音语调定制(如"老人沙哑的耳语声")
- 技术突破:NLP+语音合成实现音画毫秒级同步
3. 角色一致性引擎
案例:用Midjourney生成虚拟模特后,Veo 3在多镜头中保持同一人物形象制作香奈儿广告
- 通过跨镜头特征绑定,确保角色在不同场景中五官/服饰一致
4. 物理效果模拟
- 精准模拟:流体动力学(海浪冲击)、布料飘动等物理过程
- 技术基础:整合Generative Query Network等10+视频生成模型
5. 电影级运镜控制
| 运镜选项 | 适用场景 | 示例提示 |
|---|---|---|
| Dolly in | 强调情感 | 人物特写时推进镜头 |
| Pan Left | 场景展示 | 展示城市天际线 |
| Static | 对话场景 | 固定机位拍摄访谈 |
- 无需专业术语,点击图标即可应用好莱坞式运镜
四、创作技巧:专业导演这样用 ?
技巧1:提示词黄金公式
"角色描述+环境声+镜头语言"
示例:"穿蓝色碎花衬衫的老妇人,用沙哑嗓音兴奋低语,中景固定镜头"
技巧2:质量模式选择
| 模式 | 分辨率 | 生成时间 | 适用场景 |
|---|---|---|---|
| FAST | 720p | 约2分钟 | 快速迭代创意 |
| QUALITY | 1080p | 约8分钟 | 商业级成品输出 |
⚠️ QUALITY模式消耗AI点数达FAST的5倍(100点/次)
技巧3:一致性控制
- 首尾帧同图:上传同一图片作为首尾帧,生成循环动画
- 角色特征锁定:在提示词中明确标注"银色头发/蓝色碎花衬衫"等特征
五、立即访问:开启创作之旅 ?
访问入口
Gemini应用 → 工具栏 → 选择"视频" → 上传图片+输入提示词使用条件
- ✅ 需订阅 Google AI Ultra($124.99/月)
- ✅ 美区网络环境 + 美区Gmail账号
- ? 网页版已开放,移动端本周陆续上线
输出规格
?️ 8秒短视频 · ? 720p横屏 · ? MP4格式(含隐形SynthID水印)
? 创作人笔记:测试时尝试用老照片生成"父母爱情故事"短片,风吹裙摆的簌簌声+远处海浪声让静态照片瞬间有了呼吸…这就是AI的温度所在吧。
技术更新:帧延长功能暂不支持Veo 3,需切换Veo 2模型实现长片段生成
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...