
一、产品介绍
HumanOmniV2 由阿里巴巴通义实验室于2025年7月开源,致力于解决传统多模态模型的两大痛点:
❌ 全局上下文理解不足 → 易忽略关键背景信息
❌ 推理路径简单化 → 仅关注表面线索
通过视频+音频+文本的跨模态深度关联,模型能精准捕捉如“翻白眼背后的调侃意图”、“谎言中的微表情波动”等复杂语义。
典型案例:当分析“女性为何翻白眼”时,模型结合三人沙发聊天场景、夸张幽默语气和奇幻话题,判断这是“对敏感话题的俏皮反应”而非不满。
二、适用人群
| 人群类型 | 典型应用场景 |
|---|---|
| AI开发者 | 快速集成复杂意图理解模块 |
| 教育科技公司 | 学生情绪反馈分析系统 |
| 在线客服平台 | 客户真实需求与情绪识别 |
| 心理咨询机构 | 微表情与语音情感联合评估 |
| 内容审核团队 | 潜台词与反讽内容识别 |
三、核心功能与技术原理
以下5项能力重新定义多模态推理边界:
1. 全局上下文强制总结
- 原理:生成答案前先输出
<context>标签,结构化描述场景/表情/语调 - 作用:确保不遗漏关键线索(如0:05秒的叹息+眼神回避)
- 案例:判断演讲者情绪时,同时标注“紧握话筒+语速加快+假笑”
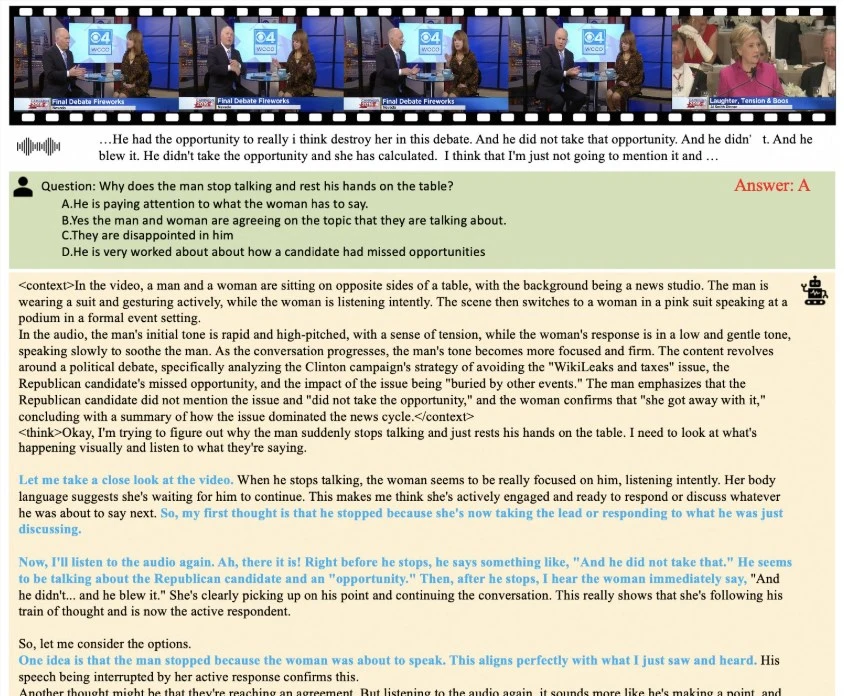
2. 四维奖励驱动训练
| 奖励类型 | 优化目标 | 技术实现 |
|---|---|---|
| 上下文奖励 | 多模态线索覆盖率 | GPT-4评估场景描述完整性 |
| 逻辑奖励▲ | 归纳/演绎推理深度 | LLM分析因果链合理性 |
| 准确性奖励 | 答案正确率 | 人工标注数据对比 |
| 格式奖励 | 输出结构化 | 正则规则校验 |
逻辑奖励(▲) 是关键创新,推动模型像侦探般串联线索(如通过语速突变+手势收缩推断谎言)
3. 动态KL散度训练
- 原理:训练初期高探索性 → 后期高稳定性
- 创新点:移除问题级归一化项 + 词元级损失计算
- 效果:长视频分析误差降低37%(对比GRPO基线)
4. 多模态关联推理
✅ 视觉:眉毛上扬幅度+手指颤抖频率
✅ 听觉:0.8秒处的呼吸停顿+音量陡降
✅ 文本:“我同意”与强笑声的矛盾
→ 结论:表面赞同实则抗拒支持跨模态矛盾检测,适用于谈判分析等高阶场景
5. 意图分层解析
1. 显性层:语音转文字内容 → “方案很棒”
2. 隐性层:
- 视觉:嘴角单边上扬15% → 讥讽微表情
- 听觉:重音落在“棒”字 → 反向强调
3. 意图还原:实际表达反对态度四、工具使用技巧
? 效果提升3原则
输入结构化
# 最佳实践:时间戳对齐多模态数据 input = { "video": "scene1_0:05-0:15.mp4", "audio": {"file": "dialogue.wav", "sample_rate": 44100}, "text": [{"time": "0:08", "content": "这太荒谬了..."}] }提示词工程
[错误方式] Q: 这个男人在生气吗?
[正确方式]
请按格式分析:
– 视觉线索:列举3个关键表情/动作
– 听觉线索:标记2处语气变化
– 文本矛盾点
3. **阈值调节**
```markdown
# 重要参数(config.json):
"sensitivity": {
"micro_expression": 0.72, # 微表情识别阈值
"tone_contradiction": 0.68 # 语音文本矛盾阈值
}五、访问地址
? 立即体验:
- GitHub源码库:
https://github.com/HumanMLLM/HumanOmniV2 - HuggingFace模型:
https://huggingface.co/PhilipC/HumanOmniV2
支持10秒快速部署,提供Colab在线Demo,无需显存要求!
最后思考:当AI能读懂“翻白眼”的幽默潜台词,捕捉到“谎言”下的微表情,我们是否正在逼近通用情感智能的奇点?HumanOmniV2的答案,藏在每帧画面0.1秒的细节里。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...