
? 产品介绍
字节跳动智能创作团队2025年推出的XVerse图像生成模型,彻底解决了传统AI绘图在多主体场景中的身份混淆难题。不同于主流扩散模型,它基于DiT(Diffusion Transformer)架构,通过创新性的偏移量调制技术,让用户能像指挥家一样,同时操控画面中每个人物、物体的身份特征与风格属性。目前该技术已在剪映、轻颜等产品中测试应用,即将开放商业API接口。
? 适用人群速查表
| 领域 | 典型场景 | 应用价值 |
|---|---|---|
| 电商广告 | 多模特产品展示图生成 | 同一商品快速适配不同形象代言人 |
| 游戏设计 | 多角色概念图创作 | 批量生成具独特技能外观的角色 |
| 医疗教育 | 解剖图多视角生成 | 动态调整器官展示细节 |
| 城市规划 | 场景效果图设计 | 灵活替换建筑/植被元素 |
| 社交平台 | 虚拟形象定制 | 精准控制面部/服饰特征 |
⚙️ 五大核心功能与技术揭秘
1. 多主体独立控制
技术原理:
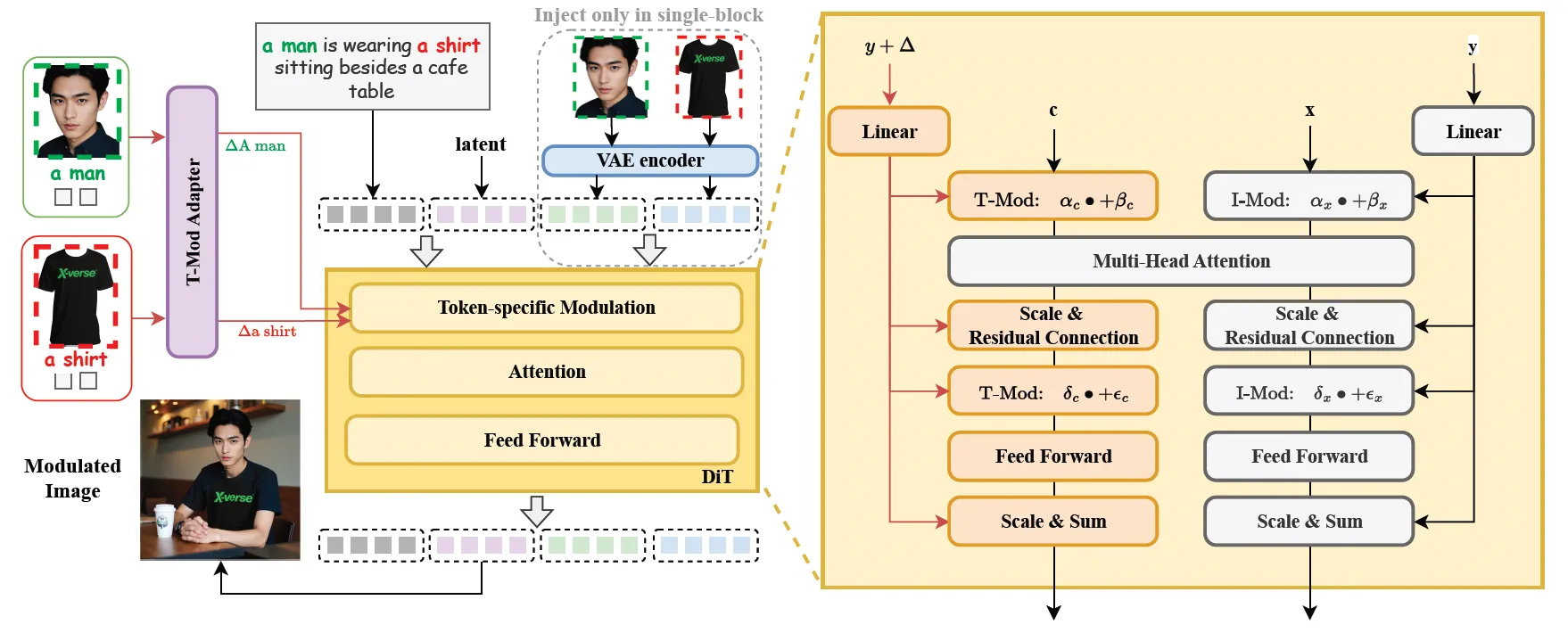
通过T-Mod适配器将参考图像转化为文本流偏移量,注入DiT的token嵌入层。每个主体分配专属偏移向量,建立与文本描述的精准映射(例如“穿红裙的女人”对应特定参考图)。
✅ 实际效果:
在一张咖啡厅场景中,可分别控制两位顾客的面容、衣着,以及桌上物品的样式,彼此特征互不干扰。
2. 高保真图像合成
技术原理:
集成VAE编码图像特征模块作为“视觉笔记员”,在单模块中保留纹理、光影等细节信息,避免伪影产生。配合区域保留损失技术,确保非修改区域的一致性。
✅ 量化表现:
XVerseBench测试中身份相似度达79.48分(满分100),显著高于同类技术。
3. 语义属性精细调节
技术原理:
采用分层控制策略:
- 共享偏移:控制整体风格与光照
- 分块偏移:在生成不同阶段调整局部属性(如早期调五官,后期调服饰)
✅ 操作示例:
上传一张侧脸照+“阳光照射”描述,即可生成同一人物在指定光影下的多角度形象。
4. 动态编辑能力
技术原理:
基于FLUX模型的动态提示解析系统,支持实时修改文本提示词(如更换服装描述),模型通过文本-图像注意力损失机制保持语义连贯性。
✅ 特色功能:检测与分割工具自动识别人脸并生成描述词,提升编辑精度。
5. 多风格适配
技术原理:
利用百万级高美学质量合成图像训练数据,结合CLIP的多模态对齐能力,实现从写实到插画风格的无缝切换。
✅ 案例表现:
同一组人物可生成水彩风插画、3D渲染图或胶片摄影风格。
?️ 四步上手技巧(附操作截图)
技巧1:分层控制法
- 上传参考图 → 2. 开启
检测与分割自动生成主体描述词 → 3. 在提示词后添加[共享偏移: 自然光][分块偏移: 微笑表情]实现分层调节注:分块偏移参数需在生成后期加入,避免早期阶段干扰结构
技巧2:多主体防混淆
- 为每个主体添加唯一标识符:
“模特A[ID01] 拿着包包B[ID02]” - 系统自动分配独立偏移量,降低特征互融风险
技巧3:细节增强指令
在高级设置中开启:
vae_detail_boost = True # 激活VAE细节增强
regularization_strength = 0.7 # 正则化强度建议值可提升发丝、织物纹理的清晰度
? 访问地址
GitHub开源库
https://github.com/bytedance/XVerse
(含快速部署脚本与Colab示例)在线体验版
https://huggingface.co/ByteDance/XVerse
(需申请测试权限)技术白皮书
https://arxiv.org/pdf/2506.21416
(详解调制机制与训练方法)
实测彩蛋:输入提示词时用括号加权可强化控制效果,例如
(精致五官:1.2)提升面部精度。期待你的创意大作! ✨
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...