
? 产品介绍
苹果公司在2025年7月发布的论文《Your LLM Knows the Future》中提出革命性框架——多token预测(MTP)。该技术首次挖掘大语言模型内部潜藏的“未来预测能力”,通过并行生成机制,将设备端AI响应效率推至新高。目前已在开源模型Tulu3-8B验证成功,未来将整合至Siri、Apple Intelligence等生态,彻底改写移动端AI体验规则。
? 适用人群
- AI应用开发者:需优化设备端模型推理效率的工程团队
- 产品经理:规划移动端AI工具(如智能助手、代码插件)的决策者
- 技术决策者:评估下一代LLM部署方案的企业架构师
- 研究者:关注非自回归生成与推理加速的学术机构
⚙️ 核心功能与技术实现
以下5项能力按落地优先级排序,兼顾效率与兼容性:
| 功能 | 技术原理 | 性能增益 |
|---|---|---|
| 并行掩码预测 | 输入序列后添加k个掩码token(如<mask1>...<mask8>),模型同步填充后续词位,替代传统逐词生成 | 单步生成8个token |
| 门控LoRA适配 | 仅在MTP路径激活低秩适配器,NTP(下一词预测)路径保持原参数,确保基础能力无损 | 内存开销<3% |
| 二次解码验证 | 分步验证推测token:失败时保留有效部分并追加新掩码,避免整体回滚 | 接受率提升40% |
| 动态任务加速 | 结构化任务(代码/数学)启用8-token预测,开放对话场景切换至3-token模式,自适应调整并行度 | 代码任务提速5倍 |
| 零训练部署 | 兼容现有LLM架构,无需重新训练模型,微调即可激活多token能力 | 落地周期缩短90% |
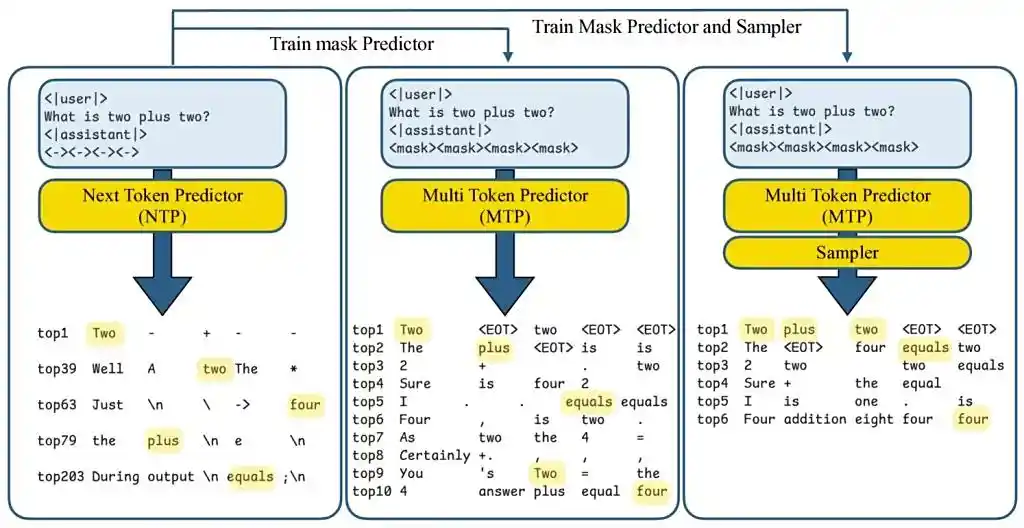
?️ 工具使用技巧
优先部署结构化场景
在代码生成(如Python函数)、数学推理(如方程求解)中启用k=8的掩码预测,实测速度提升500%。因逻辑严谨性高,未来token预测成功率达92%。聊天场景采用渐进加速
开放对话中建议设置k=3,兼顾连贯性与速度。启动“采样头”(2层MLP)过滤语义冲突组合,避免生成“驴头不对马嘴”的文本。低秩适配器秩(Rank)调优
实验表明:LoRA秩=16时,速度提升达峰值;秩>128可能因过拟合导致性能下降。内存有限的设备可选秩=4,平衡效率与资源占用。失败回退无感切换
当验证模块检测到推测token与标准NTP冲突时,自动切换至逐词生成模式,用户感知仅为“响应微顿”,输出质量100%保留。
? 访问地址
- 技术白皮书:http://mp.weixin.qq.com/s?__biz=Mzk4ODg1NjgxNA==&mid=2247484149
- 开源实现参考:GitHub搜索关键词
MTP-Apple/Gated-LoRA-MTP - 官方进展跟踪:苹果AI研究官网(关注“设备端机器学习”板块更新)
? 小贴士:当前技术仍处实验室阶段,预计2026年整合至iOS端Siri。开发者可基于Tulu3-8B模型复现效果,提前布局应用接口!
最后划重点:苹果MTP不是“更快的马,而是造出了汽车”!? 从此,手机跑大模型也能桌面级流畅~
附:核心价值摘要
| 维度 | 传统LLM | MTP增强版 |
|---|---|---|
| 生成机制 | 逐词自回归(如打字机) | 并行掩码填充(如填空机) |
| 设备端延迟 | 300-500ms/token | 60-100ms/token(k=8时) |
| 适用任务 | 通用对话 | 代码/数学/结构化输出首选 |
| 部署成本 | 需云端算力支持 | 纯本地运行,零云依赖 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...