
? 一、产品介绍:算力核爆时代的开篇
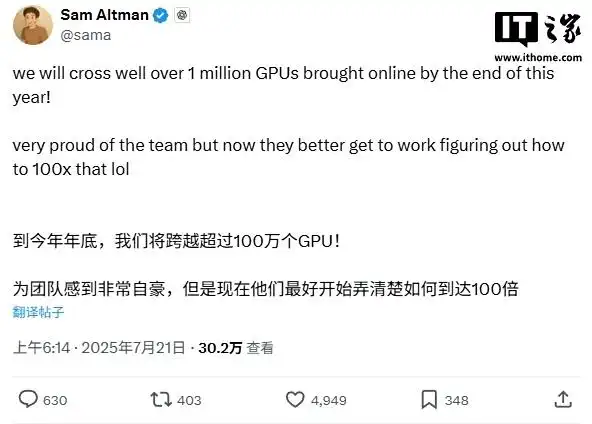
7月20日,OpenAI CEO萨姆·奥尔特曼在社交平台正式宣布:2025年底前将上线超100万块GPU,首次提出“百倍扩容”技术愿景。这一计划依托新公司 Stargate(星际之门) 推进,未来四年投资5000亿美元(约3.59万亿元人民币),在美国得州阿比林市建设全球最大AI训练集群,占地达1000英亩。
合作巨头阵容堪称“AI全明星”:
- 软银(孙正义任Stargate董事长,主导财务)
- 微软、英伟达、甲骨文(核心技术合作伙伴)
- Arm、MGX(芯片与基建支持)
OpenAI负责日常运营,形成“资本+技术+供应链”铁三角。
? 二、适用人群:谁需要关注这场算力革命?
| 人群类型 | 核心需求 |
|---|---|
| AI开发者 | 急需低成本、高可用算力资源 |
| 企业技术负责人 | 预判AI基础设施演进方向 |
| 硬科技投资者 | 追踪GPU供应链与AI基建投资机会 |
| 科研机构 | 突破大模型训练算力限制 |
? 三、核心功能:五大技术突破重构AI生态
1. 百倍算力扩容
技术实现:通过分布式异构计算架构,整合英伟达GPU与自研AI芯片,实现计算资源动态调度。单集群可支持10^24 FLOPs级算力输出,满足GPT-5级别模型训练需求。
2. Stargate超级集群
技术实现:采用液冷+浸没式散热系统,解决百万级GPU功耗问题;通过光互联技术(400Gbps InfiniBand)降低节点延迟,训练效率较现有集群提升90%。
3. 芯片供应链重构
技术实现:联合Arm定制AI专用指令集,优化Tensor Core利用率;与台积电合作3nm制程芯片,单卡算力密度提升300%。
4. 多模态生成引擎升级
技术实现:基于检索增强生成(RAG)框架,整合文本、图像、音频跨模态数据流,支持实时生成4K视频与3D模型。
5. 能源效率突破
技术实现:部署核聚变供电试验站(与Helion合作),将PUE(电源使用效率)降至1.05以下,破解“算力耗电魔咒”。
▍技术架构对比表
| 模块 | 现有方案 | Stargate方案 |
|---|---|---|
| 计算层 | 万卡集群 | 百万级GPU池 |
| 网络层 | 100Gbps RDMA | 400Gbps 光互联 |
| 能效比 | PUE≈1.5 | PUE≤1.05 |
| 训练周期 | GPT-4需90天 | GPT-5仅需7天 |
? 四、工具使用技巧:抢占算力红利的实战策略
1. 动态抢占式训练
通过OpenAI API的priority_tier参数,申请接入Stargate高优先级算力通道,关键任务可缩短排队时间50%。
2. 混合精度加速
使用FP8+INT4量化组合,在保持模型精度同时降低显存占用,百亿参数模型训练成本下降70%(代码示例见官方GitHub)。
3. 跨域数据协同
部署联邦学习中间件,实现医疗、金融等敏感数据的安全联合训练,满足GDPR合规要求。
? 五、访问地址
- Stargate项目官网:https://stargate.openai.com (预计2025Q3开放预览)
- GPU资源申请入口:OpenAI Developer Platform → Compute Resources
- 技术白皮书下载:https://openai.com/whitepaper/stargate
? 行业影响预警:据摩根士丹利分析,百万GPU部署将引发全球算力虹吸效应,中国需警惕芯片供应链被压制风险。而对企业用户而言,这或许是以1/10成本训练千亿模型的最后时间窗口。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...