? 产品介绍:谷歌AI的嵌入技术新突破
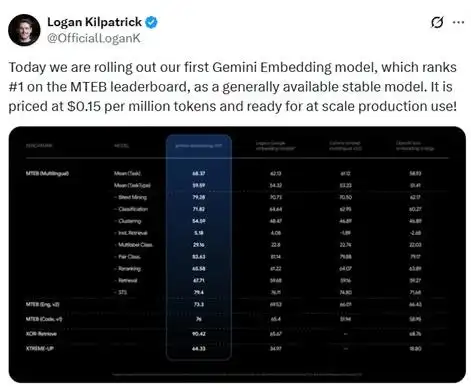
2025年7月15日,谷歌正式推出首个Gemini系列嵌入模型,在多文本嵌入基准测试MTEB中以68.37分碾压OpenAI(58.93分)。该模型基于Gemini双向Transformer架构,融合噪声对比估计(NCE)损失函数与Matryoshka表征学习(MRL)技术,支持高达3072维的语义向量输出,同时兼容动态降维至512维以节省存储空间。定价仅0.15美元/百万token,堪称目前性价比最高的工业级嵌入模型。
? 适用人群
| 群体 | 应用场景 |
|---|---|
| 开发者 | 构建语义搜索、推荐系统、聊天机器人 |
| 数据科学家 | 文本聚类、情感分析、多语言数据挖掘 |
| 留学生/研究者 | 跨语言文献检索、学术资料语义匹配 |
| 企业技术团队 | 自动化客户支持、知识库优化、文档分类 |
✨ 核心功能与技术实现
1. 多语言语义检索
- 技术原理:基于Gemini的双向注意力机制,在训练中采用合成数据生成策略——利用Gemini生成高质量跨语言查询并自动过滤低质样本。
- 效果:在MTEB双语挖掘任务中接近满分,支持超100种语言的高精度语义匹配。
2. 长文本嵌入(8K Tokens)
- 技术原理:通过分层Transformer架构处理长上下文,结合均值池化层聚合Token向量生成全局语义表示。
- 优势:适用于代码块、学术论文等长文本的语义压缩与检索。
3. 动态维度调整(MRL技术)
- 技术原理:训练时同步优化768/1536/3072维子向量,用户可截取所需维度(如仅用前512维),存储需求降低83%。
- 场景:移动端应用、低成本嵌入式设备部署。
4. 检索增强生成(RAG)优化
- 技术原理:高维向量(3072维)捕捉细粒度语义,提升与大模型结合时的上下文相关性。
- 案例:在Google Cloud企业服务中实现精准文档分析与问答系统。
5. 分类与聚类任务强化
- 技术原理:采用多阶段合成数据生成——先构建用户画像/产品信息,再生成分类标签,提升数据多样性。
- 结果:MTEB分类任务得分85.13,支持细粒度情感分析与主题识别。
? 工具使用技巧
平衡效果与成本
- 需快速检索时:使用768维嵌入,响应更快且成本更低;
- 需高精度分析时:切换至3072维模式,适配学术或商业级需求。
负样本优化策略
- 训练自定义模型时,注入硬负样本(Hard Negatives) 提升模型区分能力,避免语义混淆。
Model Soup集成
- 融合多个训练检查点参数,平均提升模型泛化性能2-3%。
? 访问地址
免费体验链接:Google AI Studio
API接入文档:Gemini Embedding开发者中心
一句话总结:更懂语义的嵌入,更懂预算的AI。无论是处理多语言学术资料,还是优化电商推荐系统,Gemini嵌入模型正在重新定义AI工作流的智能支柱。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...