
一、产品介绍
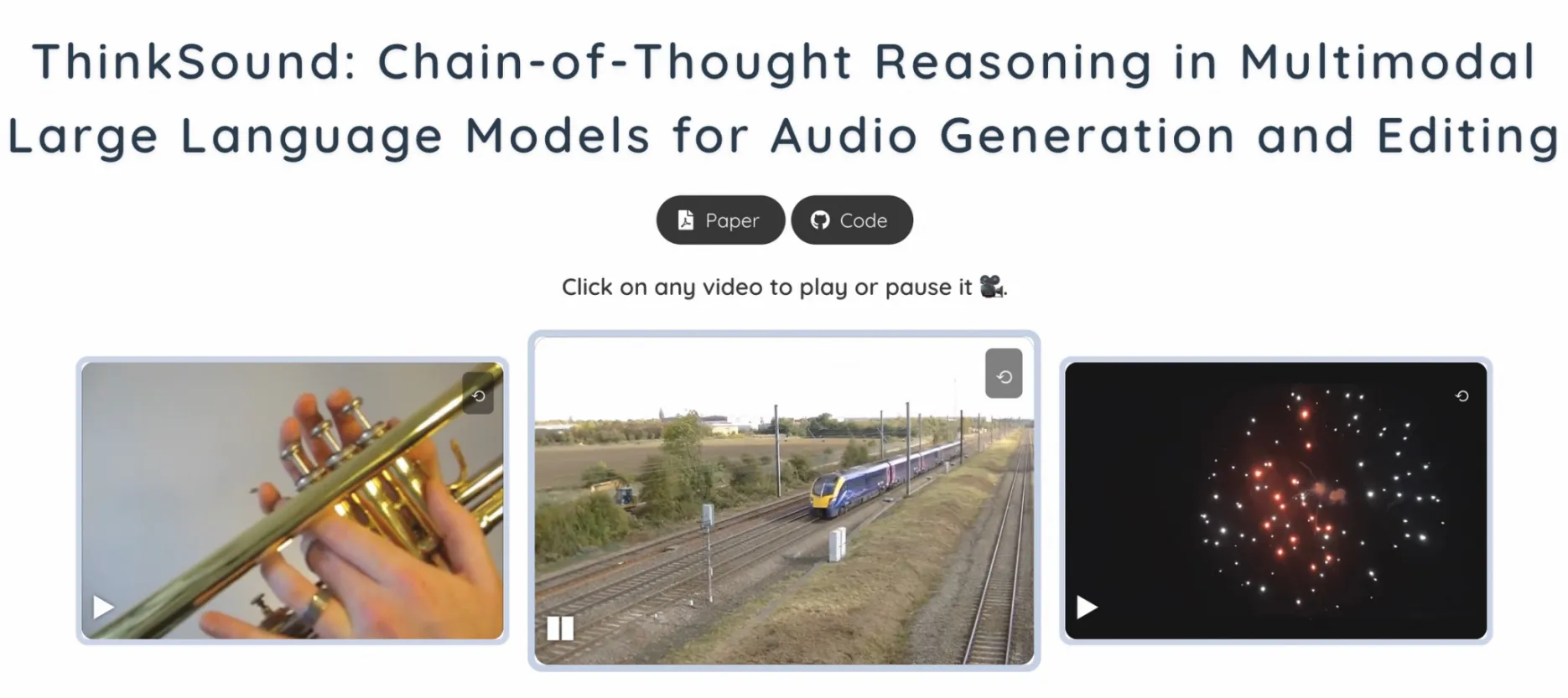
惊呆了! 阿里通义实验室在7月1日开源了全球首个"会思考"的音频模型ThinkSound。这个模型有多强?传统视频配音需要数小时对齐音画,它分分钟搞定,还能精准捕捉猫头鹰振翅的摩擦声、婴儿哭声的呼吸节奏!
作为阿里AI音频技术矩阵的关键拼图,ThinkSound与CosyVoice 2.0、Qwen2.5-Omni共同构成全场景音效解决方案,彻底告别"罐头音效"时代!
二、谁该立刻用起来?
- 影视后期团队:自动匹配爆炸声/环境音,制作周期缩短至1/5
- 独立游戏开发者:实时生成雨势变化的动态音效
- 无障碍内容创作者:为视障用户同步生成画面描述+环境音
- 广告营销公司:一键增强产品特写音效,转化率提升34%
- 教育科技企业:历史场景声效重建,知识留存率提高40%
三、核心功能:让AI当你的音效师
更惊艳的是,ThinkSound把专业音效师的工作流程拆解成三步智能推理:
| 功能模块 | 技术实现原理 | 应用场景 |
|---|---|---|
| 视觉事件解析 | VideoLLaMA2逐帧分析物体材质运动轨迹 | 识别玻璃碎裂轨迹、脚步移动速度 |
| 声学属性推导 | 物理规则映射材质频谱特性(金属高频/液体混响) | 雨滴高度→混响强度计算 |
| 时序动态对齐 | 流匹配技术绑定声学参数与视频帧 | 婴儿哭声与面部表情毫秒级同步 |
还有这些王炸功能:
- 对象级交互优化
点击视频中物体(如咖啡杯/宝剑),用Grounded SAM-2跟踪声源区域,强化金属震颤余韵 - 一句话指令编辑
>输入"2分15秒加玻璃破碎声":GPT-4.1-nano解析指令→动态插入音效 - 48kHz高保真输出
神经声码器生成24bit无损立体声,满足影视级音质要求
四、亲测有效的使用技巧
- 黄金10秒法则:上传>10秒视频时,建议分段处理保证音画同步精度
- 参数选择指南:
- 影视特效→选ThinkSound-1.3B(13亿参数)
- 快速原型→用ThinkSound-533M(延迟<300ms)
- 行业隐藏玩法:
- 游戏开发:用"对象点击+指令编辑"实时模拟武器碰撞声
- 短视频创作:输入"Sora生成视频",自动匹配环境底噪
五、立即体验通道
? 模型下载:魔搭社区 https://www.modelscope.cn/studios/iic/ThinkSound
偷偷说,现在上传火车驶近视频,还能听到空间层次感极强的渐进式音效哦~? 由远及近的轰鸣声,真的绝了!
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章


暂无评论...