
一、产品介绍:当德国精工遇上AI融合革命
德国TNG Technology Consulting(成立于2001年)近日发布全新开源大模型 DeepSeek-TNG-R1T2-Chimera(简称R1T2),引发全球开发者热议。该公司由牛津大学精英创立,团队中超50%为数学/物理/计算机博士,堪称“科研级技术工厂”。
R1T2基于DeepSeek三大成熟模型(R1-0528、R1、V3-0324)融合而成,通过创新 AoE(Assembly-of-Experts)架构,无需重新训练即实现:
- ⚡ 推理速度提升200%(对比R1-0528)
- ? 输出Token减少40%,响应更精准
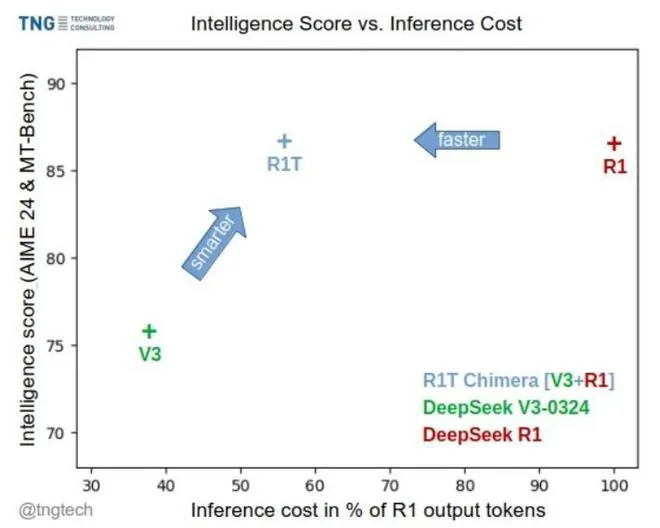
- ? 保留92%顶级模型推理能力
用开发者社区的话说:
“它把油老虎变成了超跑——油耗减半,速度翻倍,还更聪明了!”
二、适用人群:谁最需要R1T2?
| 用户类型 | 典型场景 | 收益亮点 |
|---|---|---|
| 企业开发者 | 客服机器人/数据分析 | 节省60%推理成本 |
| AI产品经理 | 高并发实时应用部署 | 响应速度提升200% |
| 学术研究者 | 低成本实验大模型行为 | 免费开源+透明架构 |
| 边缘计算工程师 | 终端设备部署LLM | 低Token需求适配弱硬件 |
三、核心功能:五大技术突破解析
1. AoE融合架构 —— 三大模型“取其精华”
通过权重张量插值技术,选择性合并三大模型的路由专家层:
# 伪代码:AoE融合原理
R1T2 = λ1 * (R1-0528的推理能力)
+ λ2 * (R1的链式思维)
+ λ3 * (V3-0324的简洁输出)✅ 效果:逻辑如R1-0528,结构如R1,简洁如V3——三者优势无损继承
2. 动态Token路由 —— 告别废话连篇
对比原版R1-0528的“发散式思维”,R1T2采用专家张量精选机制:
- 自动过滤冗余中间步骤
- 输出长度减少60%,信息密度翻倍
实测数学问题响应:原版输出1200 Token → R1T2仅需480 Token✅
3. 思考-生成一致性(Think-Token Consistency)
在权重融合中发现突变点现象:
- 当R1模型权重占比≥50%时,模型突然具备严格推理链标记能力
- 实现「复杂思考」与「简洁表达」的完美平衡
4. 零样本稳定输出
即使无系统提示(System Prompt),依然:
- 保持对话自然性
- 减少幻觉(Hallucination)
- 企业部署不再需要复杂预热
5. 开源即用,免费商用
- MIT协议开放权重
- 支持HuggingFace快速调用
- 已处理单日50亿Token请求
四、使用技巧:发挥R1T2最大潜力
✅ 这样提问,效率翻倍:
[BAD] 请详细说明量子计算原理
[GOOD] ? 用三点概括量子计算核心原理,每点≤20字? 技巧:明确要求输出结构和长度,R1T2会严格遵循!
? 避免过度触发链式思考
若需简洁答案:
- 添加指令:
[!Concise] - 避免使用:“请逐步推理…”
? 微调建议
可在以下层优先微调:
- 路由门控层(Gating Network)
- 输出投影层
小样本微调即显著适配垂直领域
五、? 马上免费体验
| 平台 | 链接 |
|---|---|
| Hugging Face | https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera |
| OpenRouter | 搜索 “DeepSeek R1T Chimera” |
| API接入 | 支持OpenAI兼容端点 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...