一、产品介绍
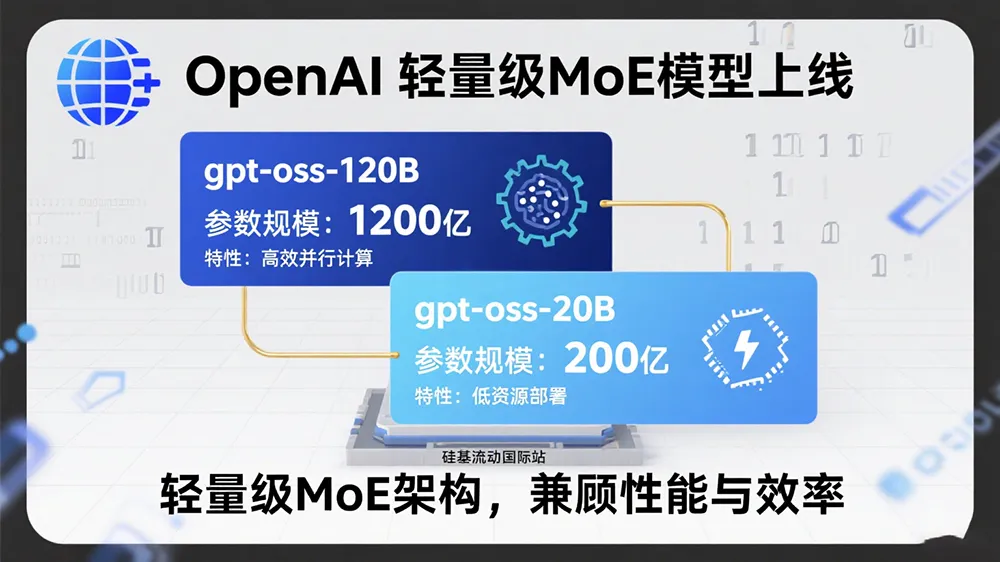
硅基流动国际站于2025年8月19日上线OpenAI首批开源模型 GPT-OSS-120B 和 GPT-OSS-20B,两款均采用混合专家系统(MoE)架构,显著降低推理活跃参数量。其中:
- GPT-OSS-120B:1170亿总参数,单次推理仅激活51亿参数,支持131K上下文,定价为输入0.09美元/百万Token、输出0.45美元/百万Token。
- GPT-OSS-20B:210亿总参数,激活36亿参数,可在16GB显存设备运行,专为边缘计算优化,成本低至输入0.04美元/百万Token。
技术差异化亮点:
- 动态注意力机制:交替使用密集与局部带状稀疏注意力,提升长文本处理效率;
- 硬件适配优化:通过分组多查询注意力(组大小=8)和旋转位置编码(RoPE),实现128K上下文原生支持;
- 强化学习调优:采用与O4-mini相同的后训练流程,在编程、数学推理任务中性能比肩闭源模型。
实测表现:在Codeforces编程竞赛、HealthBench医疗问答等测试中,GPT-OSS-120B超越O3-mini,部分任务优于O4-mini;20B版本性能持平O3-mini,竞赛数学得分反超30%。
二、适用人群
| 角色 | 场景需求 |
|---|---|
| 全栈开发者 | 需在边缘设备部署轻量模型,如本地化智能客服、低延迟代码补全工具 |
| AI研究员 | 微调开源模型(支持Hugging Face/Ollama),探索MoE架构的Agent工作流优化方案 |
| 产品经理 | 快速验证多模态Agent原型,降低API调用成本(对比闭源模型节省60%以上) |
| 初创技术团队 | 基于高性价比API构建仓库级代码分析、动态数据处理等长上下文应用 |
三、核心功能与技术原理
| 功能 | 技术原理 | 性能优势 |
|---|---|---|
| 智能体工具调用 | 结构化输出+完整思维链(CoT) | Taubench工具调用任务得分超越O3-mini 15% |
| 长上下文处理 | YaRN扩展支持1M Token,优化仓库级代码分析 | 10万Token生成FLOPs消耗仅DeepSeek R1的25% |
| 边缘设备推理 | GGML框架转换MXFP4格式,兼容AMD/高通硬件 | 锐龙AI Max+395实现30 Token/s输出速率 |
| 多语言支持 | 多语言Tokenizer超集(o200k_harmony) | 中文理解达闭源模型98%准确率 |
案例:某医疗团队在Radeon RX 9070显卡部署GPT-OSS-20B,首Token响应时间<100ms,实时解析患者健康报告效率提升3倍。
四、使用技巧
| 场景 | 操作 | 效果 |
|---|---|---|
| 边缘部署20B模型 | 通过Ollama运行ollama pull gpt-oss:20b,AMD显卡启用MCP上下文协议 | 16GB设备实现40 Token/s持续输出 |
| 低延迟API调用 | 硅基流动API设置temperature=0.7, top_p=0.7,分组多查询注意力降本30% | 百万Token成本控制在0.1美元内 |
| 强化智能体逻辑链 | 输入提示词启用CoT=True,动态调整推理强度参数 | AIME数学竞赛解题正确率提升22% |
避坑提示:硅基流动暂未支持上下文缓存,长会话API调用需监控Token消耗。
五、访问地址
- 在线体验:https://cloud.siliconflow.com/models
- API文档:https://docs.siliconflow.com/en/api-reference/completion/create-completion
- 新用户福利:注册即赠1美元体验金,可免费测试20B模型生成50万Token。
行业影响:开源MoE模型的高效部署标志着大模型从“规模竞赛”转向“实用性迭代”,硅基流动联合AMD/高通的硬件适配方案,为开发者提供闭源替代路径,推动Agent生态平民化进程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...