
一、产品介绍:小身材大智慧的端侧AI利器
阿里通义实验室于2025年8月7日推出两款革新性开源模型——Qwen3-4B-Instruct-2507与Qwen3-4B-Thinking-2507。这两款仅40亿参数的小尺寸模型专为移动端和边缘计算设计,已同步开源至魔搭社区和HuggingFace平台。
值得注意的是,MediaTek天玑9400旗舰芯片已率先完成对Qwen3系列的端侧适配,未来搭载该平台的手机将能本地化运行这些模型,实现离线环境下的高速AI响应。这标志着大模型正式进入“口袋级”实用阶段!
二、适用人群:谁需要关注这些模型?
- 移动应用开发者:为APP增加本地化AI功能(如文档分析、语音助手)
- 中小企业技术团队:低成本部署私有化AI服务,保障数据安全
- 教育机构:在机房普通显卡或学生笔记本运行AI教学实验
- 硬件厂商:为智能家居、可穿戴设备嵌入轻量AI大脑
- 个人创客:用消费级显卡(如RTX 4060)开发定制化AI工具
三、核心功能:小模型的五大突破能力
以下为两款模型的差异化能力对比与技术实现解析:
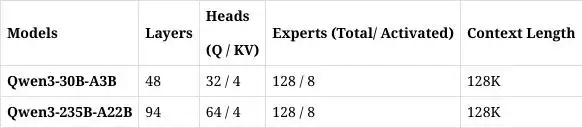
| 功能模块 | Qwen3-4B-Instruct-2507 | Qwen3-4B-Thinking-2507 | 技术原理 |
|---|---|---|---|
| 通用任务 | 超越GPT4.1-Nano | 接近30B基础模型 | 知识蒸馏+人类偏好强化学习 |
| 复杂推理 | 支持基础逻辑推理 | AIME25数学81.3分 | 思维链蒸馏+符号逻辑注入 |
| 上下文长度 | 256K tokens | 256K tokens | 分组查询注意力(GQA)优化 |
| Agent智能体 | 基础工具调用 | 超越30B推理模型 | 动态环境反馈机制 |
| 多语言支持 | 覆盖80+语言长尾知识 | 强化逻辑表达一致性 | 多语言对齐微调 |
caption: 双模型分别侧重指令跟随与深度推理,均采用MoE(混合专家)架构压缩参数规模
256K长文本处理
通过分组查询注意力(GQA)机制压缩内存占用,使小模型能分析整本小说或百页PDF,适合移动端文档摘要、合同审查等场景。数学推理突破
Thinking版本采用两步强化学习策略:首轮学习数学符号逻辑,二轮融合真实解题路径。在AIME25(国际数学竞赛题库)测试中,以4B参数量达到81.3分,超越部分70B模型。动态Agent协作
原生支持MCP跨智能体协议,可联动其他AI工具。例如在手机端调用日历API安排行程,再结合地图API规划路线,实现多任务自动化处理。人类偏好对齐优化
基于DPO(直接偏好优化)框架,在开放性问题中减少机械感回复。例如当用户询问观点类问题时,模型会生成更具人文温度的答案。
四、工具使用技巧:端侧部署实战指南
▶ 手机端极速体验(安卓/iOS)
- 下载
通义APP,在模型库选择 “Qwen3-4B-Thinking” - 开启端侧加速模式(需芯片支持NPU)
- 输入数学题或长文档提问,例如:
“解析《三体》中黑暗森林法则的哲学依据,列出3点并举例说明”
▶ 开发者本地部署(Python示例)
from transformers import AutoModelForCausalLM
# 使用4-bit量化加载模型(仅需8GB显存)
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-4B-Thinking-2507",
device_map="auto",
load_in_4bit=True
)
# 处理长文本提示词
response = model.generate("256K上下文输入...")注:搭配MediaTek Neuron Studio工具链可进一步优化推理速度
▶ 企业级方案建议
- 数据敏感场景:采用全离线部署,用消费级显卡构建本地知识库
- 硬件限制环境:启用动态计算卸载(DCO),将大计算量任务暂存至内存
五、访问地址:即刻获取资源
✅ 模型下载
- HuggingFace:
https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507 - 魔搭社区:
https://modelscope.cn/models/Qwen/Qwen3-4B-Thinking-2507
✅ 在线体验
- 通义千问官网:https://qianwen.aliyun.com
- 天玑9400真机演示:各手机品牌体验店(需确认芯片型号)
技术趋势观察:随着Qwen3-4B等小尺寸模型的开源,2025年已成为“端侧AI普及元年”。未来半年我们将看到更多手机、平板预装本地大模型,彻底改变AI依赖云端的现状。而阿里通义凭借200多款全尺寸开源模型的生态布局,正引领国产AI向“小巧、精准、可控”方向进化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章


暂无评论...