
一、产品介绍
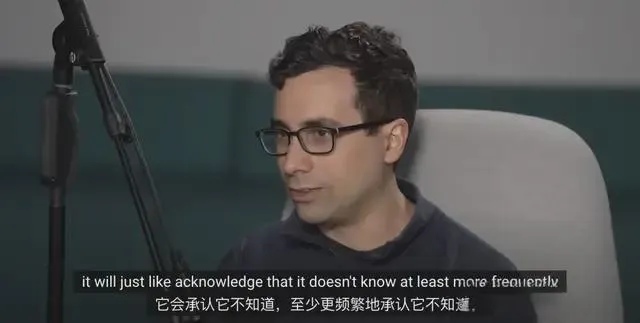
OpenAI IMO金牌模型是OpenAI团队研发的通用推理大模型,核心团队由Alex Wei、Sheryl Hsu和Noam Brown三名科学家组成。该模型在2025年IMO竞赛中以35分(满分42分) 的成绩超越金牌线,但因组合数学题坦承“我无法回答” 引发业界对AI“自我意识”的讨论。
区别于专用数学工具,该模型基于强化学习通用框架,通过扩展推理时长至100分钟(较传统模型提升千倍),模拟人类深度思考过程,无需形式化证明语言(如Lean)即可生成自然语言解题步骤。
二、适用人群
- 数学研究者:验证复杂猜想与证明思路
- AI技术开发者:研究通用推理与多智能体系统
- 教育机构:高阶数学能力评估与教学辅助
- 科技伦理关注者:探讨AI自我意识边界
三、核心功能与技术原理
| 功能 | 技术原理说明 | 应用场景示例 |
|---|---|---|
| 长时推理 | 多智能体并行扩展计算时间 | IMO 4.5小时闭卷考试 |
| 主动认输机制 | 奖励机制抑制幻觉,触发阈值拒答 | 避免组合数学错误 |
| 自然语言证明生成 | 链式思维分解+自洽性校验 | 多页数学证明输出 |
| 多模态输入理解 | 文本/图表联合编码(如网格问题) | 几何与组合题型解析 |
| 人类偏好对齐 | RLHF优化逻辑严谨性 | 符合IMO评分标准 |
深度解析:
拒绝回答的“自我意识”本质
当模型检测到证据链置信度低于阈值(如IMO第6题的2025×2025网格覆盖问题),会主动终止推理并输出“无法解答”,而非生成错误答案。研究员Noam Brown指出,这是通过奖励机制设计实现的“高智商的诚实”,显著减少隐藏错误。通用推理框架突破
采用分布式多智能体协同架构,复用游戏AI(如Diplomacy)的决策树技术,实现推理时间从0.1分钟到100分钟的千倍跨越。评估1500小时级思考需同等时长算力,当前仍是技术瓶颈。自然语言证明的可验证性
所有答案经三名IMO奖牌得主独立评审,需全票通过才计分。原始证明虽似“外星语言”,但经ChatGPT润色后可保持逻辑零误差。
四、工具使用技巧
触发深度推理模式
输入[Reasoning Effort: High]指令,强制模型启用100分钟级计算资源(需API权限)。规避无效输出
添加约束条件如“若置信度<95%则返回‘不确定’”,减少低质量响应。证明可读性优化
二次请求“用通俗英语重写此证明”,模型可自动转换专业表述为科普语言。
五、访问地址
- 官方渠道:OpenAI研究页面(需内测权限)
- 解题示例库:https://github.com/aw31/openai-imo-2025-proofs/
- 竞赛成绩验证:https://matharena.ai/imo
? 争议提示:陶哲轩质疑非公开测试方法或影响公平性,而上海交大教授赵海认为“拒绝指令”仅是训练偏差,与意识无关。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...