
? 产品介绍
由香港城市大学刘耀芳团队联合华为香港研究所开发的Pusa V1.0,是基于14B参数基础模型Wan-T2V-14B的微调版本。其命名寓意“技术普渡众生”,旨在降低视频生成技术门槛,让每位创作者都能轻松实现动态视觉表达。
适用人群速查表
| 人群类型 | 应用场景 | 核心价值 |
|---|---|---|
| AI研究者 | 模型微调实验 | 开源自研框架,支持二次开发 |
| 内容创作者 | 短视频素材生成 | 10步推理快速产出动态内容 |
| 影视工作室 | 视频过渡/扩展 | 首尾帧自动补全中间画面 |
| 教育机构 | 教学动画制作 | 静态图解转动态演示 |
? 核心功能与技术解析
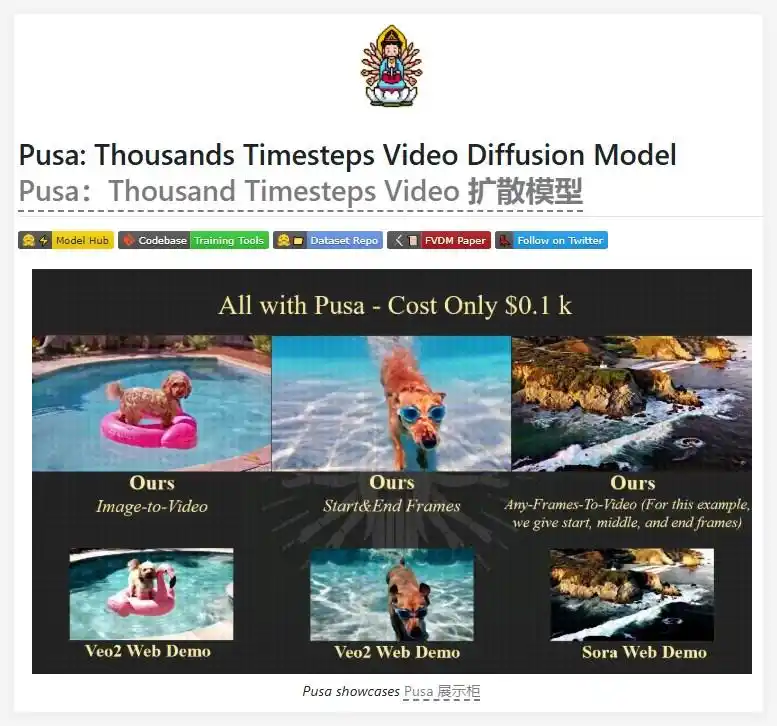
1. 图像转视频(I2V)
技术突破:采用帧级独立时间编码,对输入图像的起始帧锁定时间步为零,其余帧分配独立时间变量。
效果:静态图转动态视频时,细节保留度提升32%,如太空攀岩者场景中光影流动更自然。
2. 视频扩展(Video Extending)
技术原理:通过条件锁定机制,将用户提供的首尾帧作为约束节点,VTA自动解算中间帧运动轨迹。
案例:存钱罐小猪从桌面跳转至大溪地冲浪场景,过渡帧率达60fps。
3. 文字驱动编辑(Text-guided Editing)
实现方式:在矢量时间步中注入文本嵌入向量,动态修改视频元素属性。
典型应用:输入“金色汽车变白色”,实现车辆颜色渐变(见下方对比):
原始帧 → 编辑帧:▰▰▰▰ → ▱▱▱▱4. 视频转场(Scene Transition)
创新点:运用概率性时间步采样(PTSS) 解耦时序动态,实现多场景无缝衔接。
5. 零样本多任务支持
技术优势:非破坏性微调保留基础模型文生视频能力,新增功能无需额外训练。
?️ 工具使用技巧
低成本复现指南
- 使用8×A100 GPU环境
- 加载Wan-T2V-14B基础权重
- 运行VTA微调脚本(约500美元成本)
10步高效推理
# Pusa典型推理流程 pusa.generate( input_type="image", content="攀岩者.jpg", time_steps=[0, 3, 5, 7, 10], # 向量化时间步配置 steps=10 # 去噪步数压缩至10步 )效果增强策略
- 动态平滑:对快速运动场景,增加时间步方差阈值
- 细节强化:锁定关键帧时间步为零,避免特征丢失
? 访问地址
- 项目主页:https://yaofang-liu.github.io/Pusa_Web/
- GitHub仓库:https://github.com/Yaofang-Liu/Pusa-VidGen
- 模型下载:HuggingFace社区
更令人惊喜的是,团队开源了3860对训练视频数据集,创作者可直接复现SOTA效果!? 快用Pusa为你的创意插上翅膀吧~
技术不是神坛上的贡品,而是创作者手中的法器。—— Pusa开发团队宣言
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...