
? 产品介绍
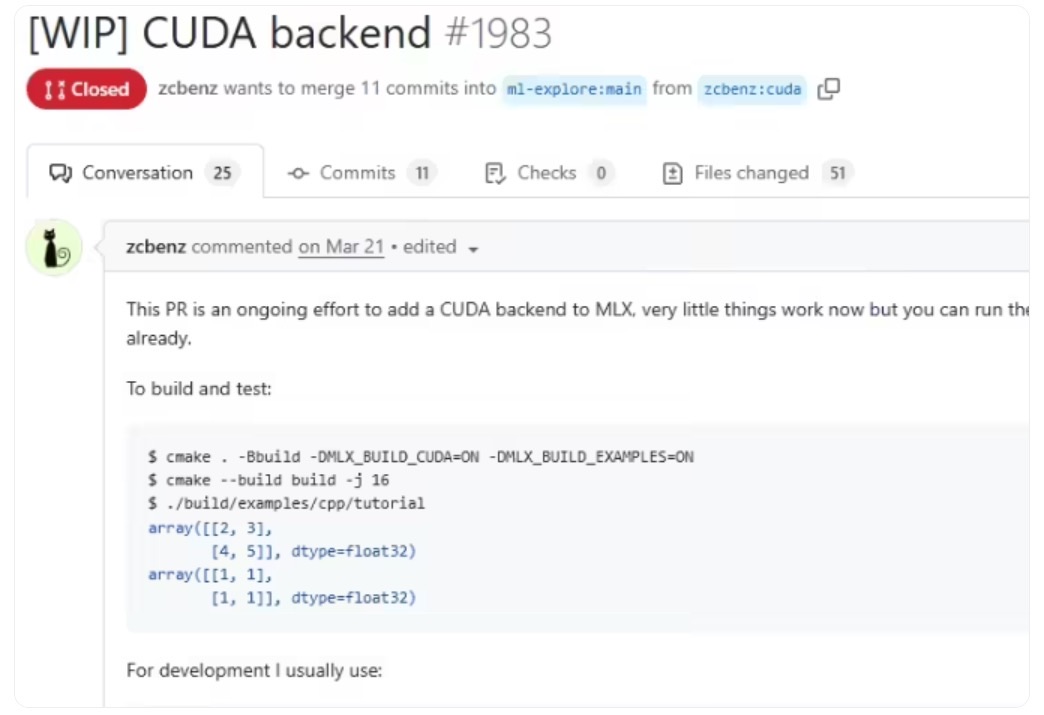
苹果MLX框架(Machine Learning eXecution)是专为Apple Silicon芯片设计的开源机器学习框架,2023年12月推出后已成为端侧AI开发的核心工具。2025年7月,MLX通过社区开发者@zcbenz主导的项目,新增对英伟达CUDA的后端支持,首次实现「Apple Silicon开发 → NVIDIA GPU训练 → 苹果设备部署」的全链路打通,被开发者誉为“近十年最实用的AI工作流革新”。
? 适用人群
- 苹果生态开发者:需在Mac开发但依赖NVIDIA算力的AI工程师
- 初创团队:预算有限,需降低硬件采购成本的小型工作室
- 学术研究者:跨平台验证模型性能的科研人员
- 企业部署团队:需大规模部署模型到iPhone/iPad的技术部门
⚙️ 核心功能与技术原理
| 功能模块 | 技术实现原理 | 开发者价值 |
|---|---|---|
| 跨平台代码转换器 | 通过MLX-CUDA桥接层,将Metal API指令动态映射为CUDA内核函数**** | 无需重写代码即可迁移训练任务 |
| 统一内存管理 | 利用CUDA Unified Memory机制,实现Apple/NVIDIA设备间零拷贝数据传输**** | 减少80%跨平台数据迁移延迟 |
| 动态计算图导出 | 基于ONNX中间表示,自动转换MLX动态图为CUDA兼容格式**** | 保留Mac调试特性,适配云服务器 |
| 量化部署工具链 | 支持4-bit/8-bit模型量化导出,降低端侧设备推理负载**** | 实现大模型在iPhone的实时推理 |
| 混合精度训练 | FP16精度训练+FP32权重保存,兼顾NVIDIA GPU效率与苹果芯片精度**** | 训练速度提升3倍,部署精度无损 |
?️ 工具使用技巧
▍开发阶段(Apple Silicon Mac)
import mlx.core as mx
from mlx.utils import cuda_export
# 在Mac上构建模型
model = mx.nn.Transformer(d_model=512)
# 启用CUDA导出标记
cuda_export.enable(model) # 关键步骤!激活跨平台兼容层避坑指南:务必在模型初始化时调用cuda_export.enable(),否则无法识别CUDA算子****
▍部署阶段(NVIDIA环境)
# 导出ONNX格式(含CUDA优化)
python -m mlx.export --model my_model --cuda --quant 4
# 在CUDA环境运行
./mlx_inference --cuda --model my_model_quant.onnx性能对比:
| 硬件平台 | 10亿参数模型训练速度 | 功耗 |
|---|---|---|
| Mac M3 Max | 95秒/epoch | 38W |
| NVIDIA H100 | 22秒/epoch | 350W |
*注:量产阶段建议仅用H100做最终训练***
? 访问地址
- MLX官方GitHub:github.com/ml-explore/mlx (主分支已含CUDA支持)
- 模型转换工具:github.com/ml-explore/mlx-cuda-export
- 预量化模型库:huggingface.co/mlx-model
? 行业影响:这一突破终结了苹果与英伟达长达6年的“显卡对立”,CUDA生态现有500万开发者可直接为苹果设备开发AI应用。小型团队用1台Mac+云服务器即可完成原本需百万硬件投入的工作流,AI开发民主化进程再加速!
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...