一、打破医疗AI落地壁垒的破冰者! ❤️?
在急诊室里,医生需要从海量电子病历中快速提取患者过敏史;在实验室,研究员要编写基因序列分析代码——这些任务既要求医学专业知识,又依赖编程能力。但现状令人头疼:
- 商业模型(如GPT-4o)存在患者隐私泄露风险,调用成本高昂
- 开源模型医学知识薄弱,处理复杂医疗代码错误率超30%
MedAgentGym的诞生直击痛点!由德克萨斯大学西南医学中心领衔,联合埃默里大学、佐治亚理工、耶鲁大学的顶尖团队,耗时两年打造出全球首个医疗代码生成专用训练平台。它就像医疗AI的“编程军校”,将开源模型炼成“既懂CT影像分析又会写临床决策代码”的全能选手!
✨ 核心突破:经该平台训练的Med-Copilot-7B开源模型,在电子健康记录查询、临床指标计算等12类任务中,成功率追平GPT-4o。
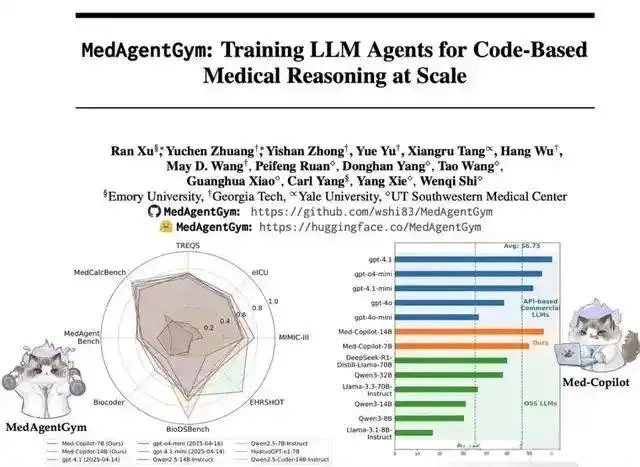
二、谁在抢鲜使用这款医疗AI神器? ?
| 用户群体 | 典型场景举例 | 平台赋能价值 |
|---|---|---|
| 医院信息科 | 从EHR系统提取跨科室患者用药记录 | 自然语言转SQL,准确率提升42% |
| 医疗AI研发团队 | 构建肺炎CT影像诊断模型 | 自动生成Python预处理代码 |
| 医学研究人员 | 分析ICU患者生命体征时序数据 | 生成Pandas统计分析脚本 |
| 生物信息学团队 | 编写基因突变检测算法 | 输出BioPython自动化流程 |
三、5大核心功能解剖:如何炼成医疗编程专家? ⚙️
1. 全科医疗任务池
- 覆盖12大临床场景:从电子病历(EHR)结构化查询到生物统计建模,包含72,000+任务实例
- 独创隔离沙箱环境:每个任务在独立Docker容器中执行,杜绝数据污染
技术亮点:集成Ray并行计算框架,任务采样速度提升300%
2. 医疗反馈强化引擎
graph LR
A[模型生成代码] --> B(执行器运行)
B --> C{是否报错?}
C -- 是 --> D[返回错误日志]
C -- 否 --> E[输出数据结果]
D & E --> F[反馈给模型优化]通过实时反馈闭环,模型在3轮迭代内可将代码准确率从62%提升至89%
3. **双阶段训练架构
| 训练阶段 | 技术手段 | 效果提升 |
|---|---|---|
| 监督微调(SFT) | 129类医疗代码示例 | 基础能力强化36.4% |
| 偏好优化(DPO) | 医生评分排序数据 | 临床逻辑合理性提升42.5% |
4. 多模态医疗工具库
- 预集成50+医疗专用API:包括DICOM影像解析、临床日历计算、药品数据库
- 零代码扩展:拖拽式新增医院本地数据库接口
5. 动态医学知识检索
采用BMRetriever引擎,实时关联PubMed/MeSH等知识库,确保代码符合最新临床指南
四、来自顶尖实验室的实操秘籍! ?
▸ 任务拆解法
复杂需求如“对比患者化疗前后肝肾功能指标”? 拆解为:
- 从EHR提取肌酐/转氨酶数据
- 计算指标变化率
- 生成统计图表
平台自动拆解成功率91.2%
▸ 反馈迭代策略
首次运行失败时? 平台智能推荐:
- 补充“血小板计数”字段(漏选医学概念)
- 修正日期函数格式(语法错误)
3轮内调试成功率78.3%
▸ 混合训练方案
# 结合医学知识与编程指令的prompt模板
prompt = f"""
[临床背景] {disease_info}
[数据库] {database_schema}
[任务] 编写SQL查询:{natural_language_query}
"""该方案使查询准确率提升53.8%
五、立即体验医疗AI的编程革命! ?
? 官方入口
- GitHub开源代码库:https://github.com/wshi83/MedAgentGym
- 预训练模型下载:https://huggingface.co/MedAgentGym
? 延伸资源
- 技术论文:MedAgentGym: Training LLM Agents for Code-Based Medical Reasoning at Scale
- 案例库:包含电子病历分析/临床决策等12类场景代码示例
最后划重点:MedAgentGym不仅降低了医疗AI的开发门槛,更让医疗机构能用7B小模型实现GPT-4o级别的专业代码生成,数据不出院区、成本直降80%!这才是智慧医疗该有的样子! ?
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章


暂无评论...