
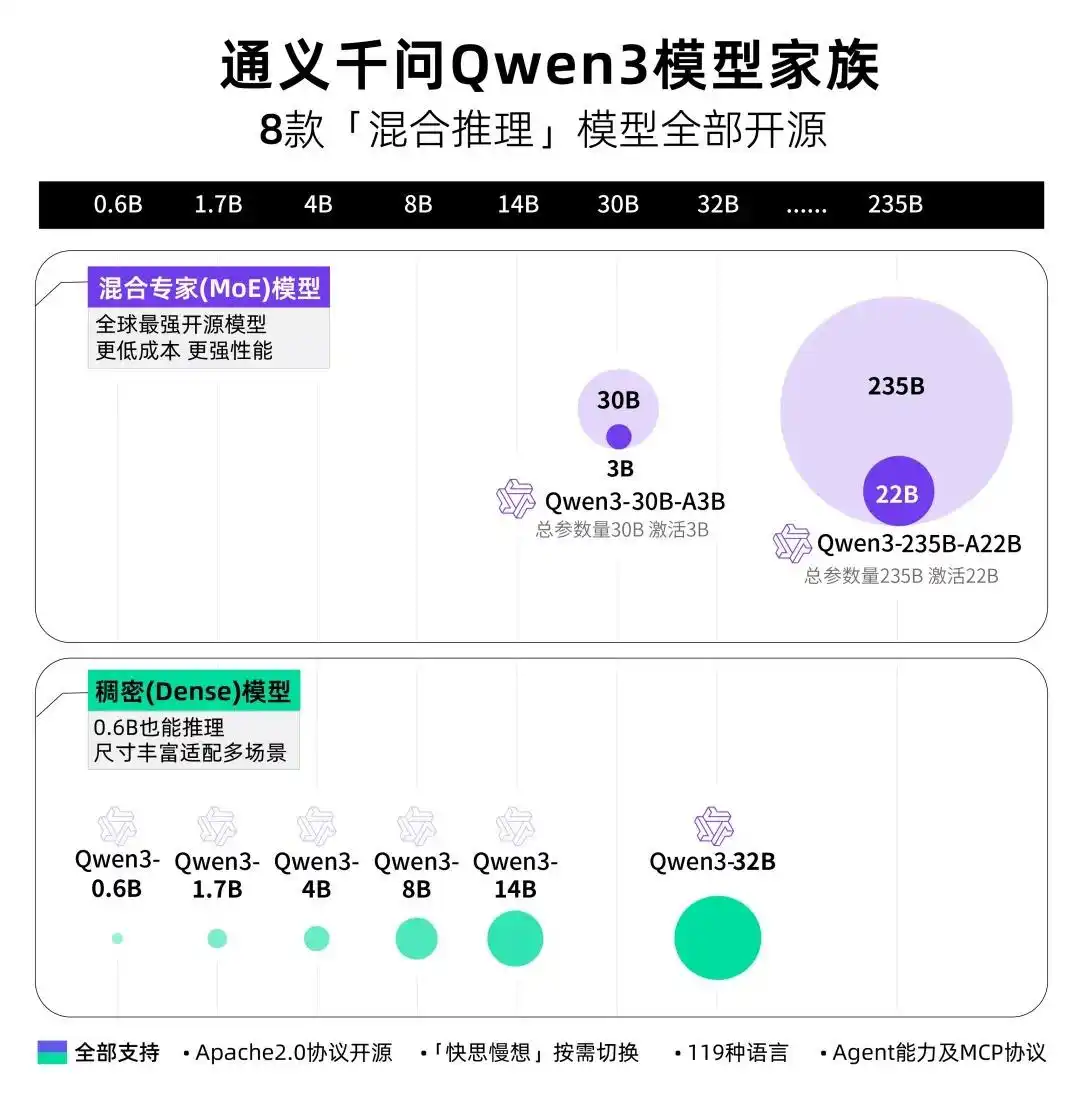
一、产品介绍:改写AI算力规则的颠覆者
Groq——这家由谷歌TPU创始团队打造的硅谷芯片新锐(2016年成立),正以火箭式速度改写AI推理市场规则。创始人Jonathan Ross曾领导谷歌首代TPU研发,团队集结英特尔、AWS硬件大牛,垂直整合战略从芯片设计直通云服务,构建全栈壁垒。最新融资将助其快速兑现沙特15亿美元合作承诺,冲刺全球AI基础设施第一梯队。

二、适用人群:谁在抢滩Groq生态?
- 大模型开发者:需超低延迟部署Llama/Gemma等开源模型
- 企业IT决策者:寻求替代英伟达的高性价比推理方案
- 实时应用厂商:聊天机器人、金融分析、医疗诊断等场景
- 中东科技企业:接入沙特达曼AI集群的本地化服务
三、核心功能:LPU如何碾压GPU?
Groq LPU的五大技术杀招与实现原理:
| 功能 | 性能表现 | 技术原理 |
|---|---|---|
| 推理加速 | 500 token/s (10倍于GPT-4) | 时序指令集架构+230MB片上SRAM,内存带宽80TB/s |
| 能效优化 | 1-3焦耳/token (GPU的1/10) | 静态编译调度消除芯片级冗余计算,光纤直连LPU集群 |
| 多模型支持 | Llama/Mistral全系兼容 | 编译器动态适配TensorFlow/PyTorch框架,自动优化算子 |
| 阿拉伯语优化 | Allam双语模型专属加速 | 沙特达曼数据中心本地化部署,8天极速建站 |
| 确定性推理 | 微秒级响应波动 | 软件定义硬件架构,编译器预调度所有指令单元 |
技术深挖:
- SRAM革命:用230MB片上SRAM替代HBM显存,消除数据搬运瓶颈,内存访问延迟降至纳秒级
- 编译即硬件:Groq编译器将AI模型转化为机器码时,同步生成芯片物理层执行路径,实现零运行时调度
四、工具使用技巧:开发者实战指南
免费尝鲜路径
→ 登录GroqCloud Playground,无需配置直接运行Llama 3 70B模型
→ 输入!speedtest命令实测吞吐量,对比本地GPU环境生产环境部署
# 使用Groq Python SDK部署双语模型 from groq import Groq client = Groq(api_key="YOUR_KEY") response = client.chat.completions.create( model="allam-arabic-english", # 沙特定制模型 messages=[{"role": "user", "content": "توليد تقرير مالي بالعربية"}] )注:调用达曼集群需选择
region=damman参数,延迟低于50ms成本控制秘诀
→ 启用动态批处理:将小请求捆绑提交,LPU利用率提升至90%+
→ 设置max_time=0.5:强制500ms内返回,避免长文本吃掉算力
五、访问地址
? GroqCloud开发者平台:https://console.groq.com
? 沙特达曼集群预约:contact@aramcodigital.sa (需沙特合作项目认证)
行业风向:随着沙特149亿美元AI基金注入,Groq等基建厂商正成为地缘科技博弈关键棋子。其LPU能否撼动英伟达王座?答案藏在每一次
import groq的代码选择中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章


暂无评论...