
一、产品定位:医疗AI开发新起点
开发方:Google DeepMind与Google Research联合研发,隶属于健康AI开发者基础模型(HAI-DEF) 生态
核心目标:
通过开源轻量化模型解决医疗AI落地三大痛点:
✅ 隐私敏感数据本地化处理需求
✅ 基层机构算力资源受限
✅ 跨模态医疗数据(影像+文本)联合分析
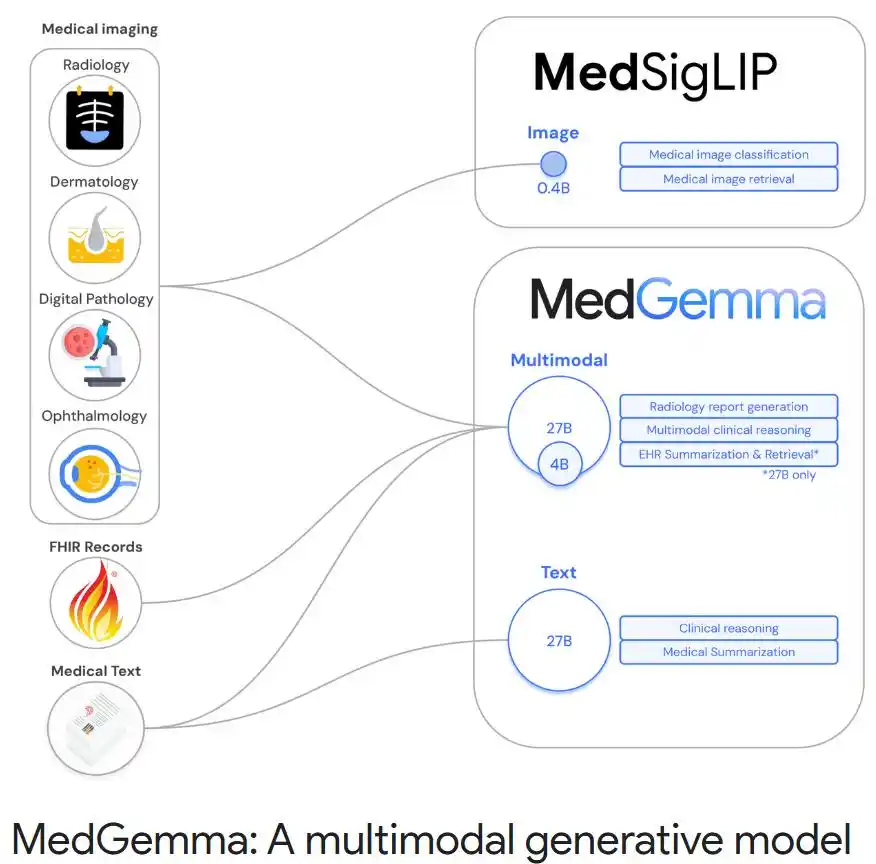
二、适用人群精准匹配
| 用户类型 | 典型场景 | 推荐模型 |
|---|---|---|
| 三甲医院 | 影像报告自动生成、辅助决策 | MedGemma 27B多模态版 |
| 基层诊所 | 移动端影像初筛、快速分诊 | MedSigLIP + MedGemma 4B |
| 医学研究者 | 电子病历深度挖掘、病理分析 | MedGemma 27B文本版 |
| AI开发者 | 定制化医疗应用开发 | 全系列模型微调 |
三、核心功能与技术实现
1. 多模态医疗决策(MedGemma 27B)
技术架构:视觉编码器(ViT变体) + 文本编码器(Transformer) → 跨模态融合层
▶️ 支持896×896高分辨率医学影像与临床文本联合输入
▶️ 在MedQA医学推理测试中达87.7%准确率,超越前代闭源模型Med-PaLM 2
临床验证:
- 美国认证放射科医师判定81%的胸部X光报告达到临床可用标准
- 皮肤病分类准确率88%(ISIC数据集),媲美专科医生
2. 轻量化影像编码(MedSigLIP)
突破性设计:
▸ 仅4亿参数的Sigmoid损失架构
▸ 适配Intel Core Ultra系列iGPU/NPU,功耗降低35%
▸ 覆盖四类关键影像:胸部X光、皮肤镜图像、眼底照片、病理切片
边缘计算表现:
| 任务类型 | 硬件环境 | 延迟 |
|---|---|---|
| X光片分类 | Intel Core Ultra 7 | ≤25ms |
| 皮肤病检索 | 骁龙8 Gen3移动平台 | ≤0.5s |
3. 电子健康记录深度解析
▶ 独家支持纵向电子病历分析(如患者历史病程追踪)
▶ 中文医学文本处理能力获台湾长庚医院验证
▶ 病历摘要生成效率较通用LLM提升30%
4. 开源生态优势
graph LR
A[模型获取] --> B(Hugging Face开源)
A --> C(Google Vertex AI云部署)
B --> D[支持LoRA微调]
C --> E[HTTPS端点大规模应用]
D --> F[定制化病理/眼科模型]四、开发者使用技巧
高效微调方案
# 使用LoRA适配器快速优化(示例)
from medgemma import load_from_hf
model = load_from_hf("MedGemma-4B")
model.add_adapter(lora_rank=64, target_modules=["q_proj","v_proj"])
model.train(dataset="胸部X光-自定义数据集")参数调优建议:
- 影像分类任务:优先冻结文本编码器,微调视觉层
- 报告生成任务:启用分组查询注意力(GQA) 提升长文本效率
部署优化策略
| 硬件配置 | 推荐方案 | 内存占用 |
|---|---|---|
| 移动端 | MedSigLIP + INT8量化 | ≤400MB |
| 边缘设备 | MedGemma 4B + ONNX Runtime | 3GB |
| 单GPU服务器 | MedGemma 27B + IPEX-LLM加速 | 12GB |
五、访问地址与资源
官方渠道:
➤ Hugging Face模型库:
实战工具:
▸ GitHub医疗微调示例
▸ Colab笔记本:零代码实现胸部X光报告生成
行业影响:美国DeepHealth已集成MedSigLIP优化X光分诊流程,印度Tap Health用MedGemma实现病程记录自动化总结。当医疗AI遇上开源轻量化,基层诊疗的「智能革命」正在推开最后一公里的大门。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...